Introduction
In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. This comprehensive overview delves into the sophisticated capabilities of Striim for Snowflake data ingestion, spanning from file-based initial loads to the advanced Snowpipe streaming integration.
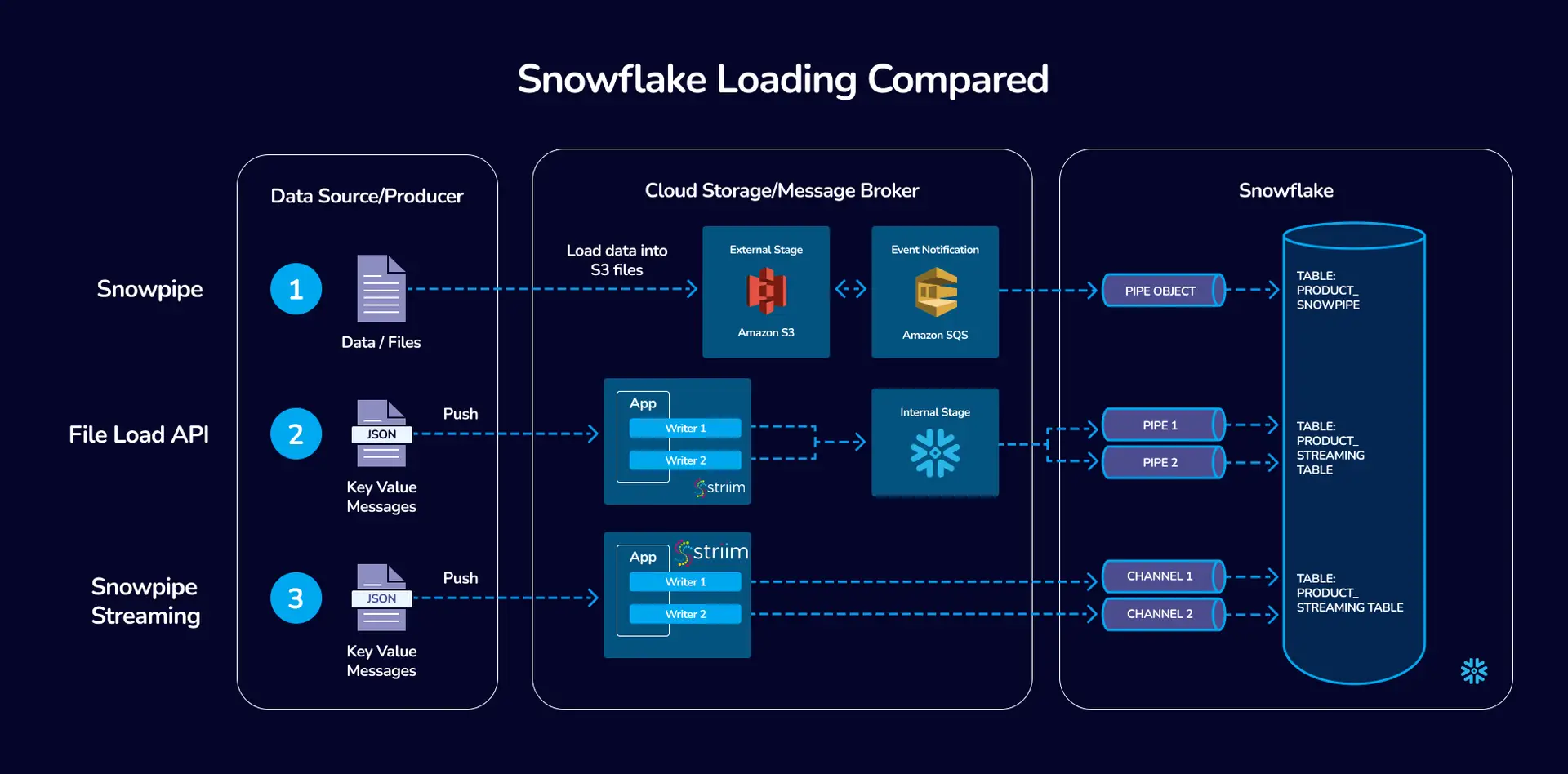
Quick Compare: File-based loads vs Streaming Ingest
We’ve provided a simple overview of the ingestion methods in this table:
| Feature/Aspect | File-based loads | Snowflake Streaming Ingest |
|---|---|---|
| Data Freshness SLAs | 5 minutes to 1 hour | Under 5 minutes. Benchmark demonstrated P95 latency of 3 seconds with 158 gb/hr of Oracle CDC ingest. |
| Use Cases | – Ideal for batch processing and reporting scenarios – Suitable for scenarios where near real-time data is not critical – Bulk data uploads at periodic intervals |
– Critical for operational intelligence, real-time analytics, AI, and reverse ETL – Necessary for scenarios demanding immediate data actionability – Continuous data capture and immediate processing |
| Data Volume Handling | Efficiently handles large volumes of data in batches | Best for high-velocity, continuous data streams |
| Flexibility | Limited flexibility in terms of data freshness – Good for static, predictable workloads |
High flexibility to handle varying data rates and immediate data requirements – Adaptable to dynamic workloads and suitable for AI-driven insights and reverse ETL processes |
| Operation Modes | Supports both Append Only and Merge modes | Primarily supports Append Only mode |
| Network Utilization | Higher data transfer in bulk, but less frequent – Can be more efficient for network utilization in certain scenarios |
Continuous data transfer, which might lead to higher network utilization |
| Performance Optimization | Batch size and frequency can be optimized for better performance – Easier to manage for predictable workloads |
Requires fine-tuning of parameters like MaxRequestSizeInMB, MaxRecordsPerRequest, and MaxParallelRequests for optimal performance – Cost optimization is a key benefit, especially in high-traffic scenarios |
File-based uploads: Merge vs Append Only
Striim’s approach to loading data into Snowflake is marked by its intelligent use of file-based uploads. This method is particularly adept at handling large data sets securely and efficiently. A key aspect of this process is the choice between ‘Merge’ and ‘Append Only’ modes.
Merge Mode: In this mode, Striim allows for a more traditional approach where updates and deletes in the source data are replicated as such in the Snowflake target. This method is essential for scenarios where maintaining the state of the data as it changes over time is crucial.
Append Only Mode: Contrarily, the ‘Append Only’ setting, when enabled, treats all operations (including updates and deletes) as inserts into the target. This mode is particularly useful for audit trails or scenarios where preserving the historical sequence of data changes is important. Append Only mode will also demonstrate higher performance in workloads like Initial Loads where you just want to copy all existing data from a source system into Snowflake.
Snowflake Writer: Technical Deep Dive on File-based uploads
The SnowflakeWriter in Striim is a robust tool that stages events to local storage, AWS S3, or Azure Storage, then writes to Snowflake according to the defined Upload Policy. Key features include:
- Secure Connection: Utilizes JDBC with SSL, ensuring secure data transmission.
- Authentication Flexibility: Supports password, OAuth, and key-pair authentication.
- Customizable Upload Policy: Allows defining batch uploads based on event count, time intervals, or file size.
- Data Type Support: Comprehensive support for various data types, ensuring seamless data transfer.
SnowflakeWriter efficiently batches incoming events per target table, optimizing the data movement process. The batching is controlled via a BatchPolicy property, where batches expire based on event count or time interval. This feature significantly enhances the performance of bulk uploads or merges.
Batch tuning in Striim’s Snowflake integration is a critical aspect that can significantly impact the efficiency and speed of data transfer. Properly tuned batches ensure that data is moved to Snowflake in an optimized manner, balancing between throughput and latency. Here are key considerations and strategies for batch tuning:
Snowpipe Streaming: Unleashing Real-Time Data Integration and AI
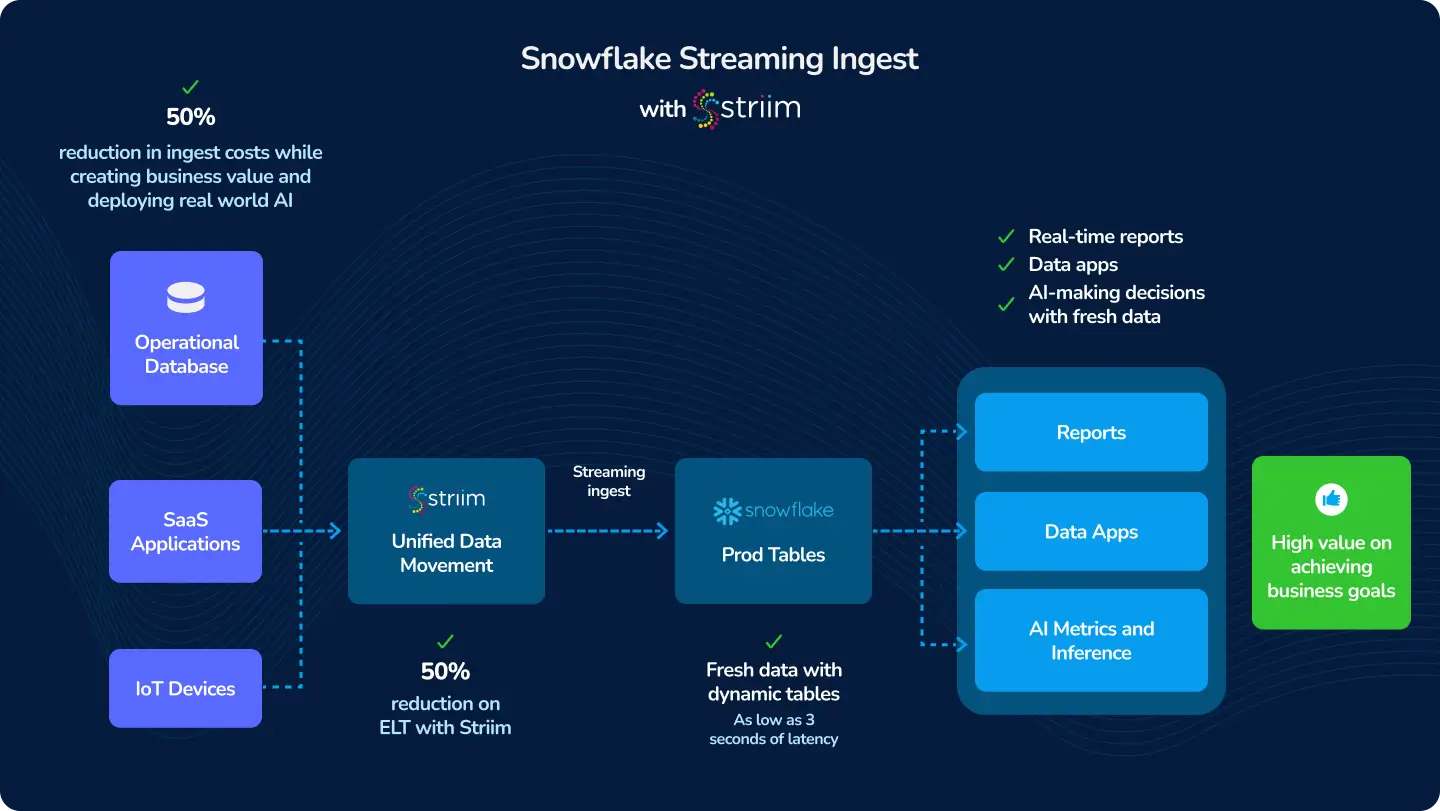
Snowpipe Streaming, when teamed up with Striim, is kind of like a superhero for real-time data needs. Think about it: the moment something happens, you know about it. This is a game-changer in so many areas. For instance, in banking, it’s like having a super-fast guard dog that barks the instant it smells a hint of fraud. Or in online retail, imagine adjusting prices on the fly, just like that, to keep up with market trends. Healthcare? It’s about getting real-time updates on patient stats, making sure everyone’s on top of their game when lives are on the line. And let’s not forget the guys in manufacturing and logistics – they can track their stuff every step of the way, making sure everything’s ticking like clockwork. It’s about making decisions fast and smart, no waiting around. Snowpipe Streaming basically makes sure businesses are always in the know, in the now.
Striim’s integration with Snowpipe Streaming represents a significant advancement in real-time data ingestion into Snowflake. This feature facilitates low-latency loading of streaming data, optimizing both cost and performance, which is pivotal for businesses requiring near-real-time data availability.
- Cost and Performance Efficiency: Striim’s use of Snowpipe Streaming demonstrates over 95% cost savings and an average P95 latency of just 3 seconds for high traffic tables.
- Versatile Source Connectivity: Striim offers a wide array of streaming source connectors including databases like Oracle, Microsoft SQL Server, MongoDB, PostgreSQL, IoT streams, Kafka, and many more.
- Industry-leading benchmarks: In collaboration with industry experts, Striim has thoroughly benchmarked the Snowpipe Streaming API in their new Snowflake Writer, validating its efficacy in cost optimization and performance.
Choosing the Right Streaming Configuration in Striim’s Integration with Snowflake
The performance of Striim’s Snowflake writer in a streaming context can be significantly influenced by the correct configuration of its streaming parameters. Understanding and adjusting these parameters is key to achieving the optimum balance between throughput and responsiveness. Let’s delve into the three critical streaming parameters that Striim’s Snowflake writer supports:
- MaxRequestSizeInMB:
- Description: This parameter determines the maximum size in MB of a data chunk that is submitted to the Streaming API.
- Usage Notes: It should be set to a value that:
- Maximizes throughput with the available network bandwidth.
- Manages to include data in the minimum number of requests.
- Matches the inflow rate of data.
- MaxRecordsPerRequest:
- Description: Defines the maximum number of records that can be included in a data chunk submitted to the Streaming API.
- Usage Notes: This parameter is particularly useful:
- When the record size for the table is small, requiring a large number of records to meet the MaxRequestSizeInMB.
- When the rate at which records arrive takes a long time to accumulate enough data to reach MaxRequestSizeInMB.
- MaxParallelRequests:
- Description: Specifies the number of parallel channels that submit data chunks for integration.
- Usage Notes: Best utilized for real-time streaming when:
- Parallel ingestion on a single table enhances performance.
- There is a very high inflow of data, allowing chunks to be uploaded by multiple worker threads in parallel as they are created.
The integration of these parameters within the Snowflake writer needs careful consideration. They largely depend on the volume of data flowing through the pipeline and the network bandwidth between the Striim server and Snowflake. It’s important to note that each Snowflake writer creates its own instance of the Snowflake Ingest Client, and within the writer, each parallel request (configured via MaxParallelRequests) utilizes a separate streaming channel of the Snowflake Ingest Client.
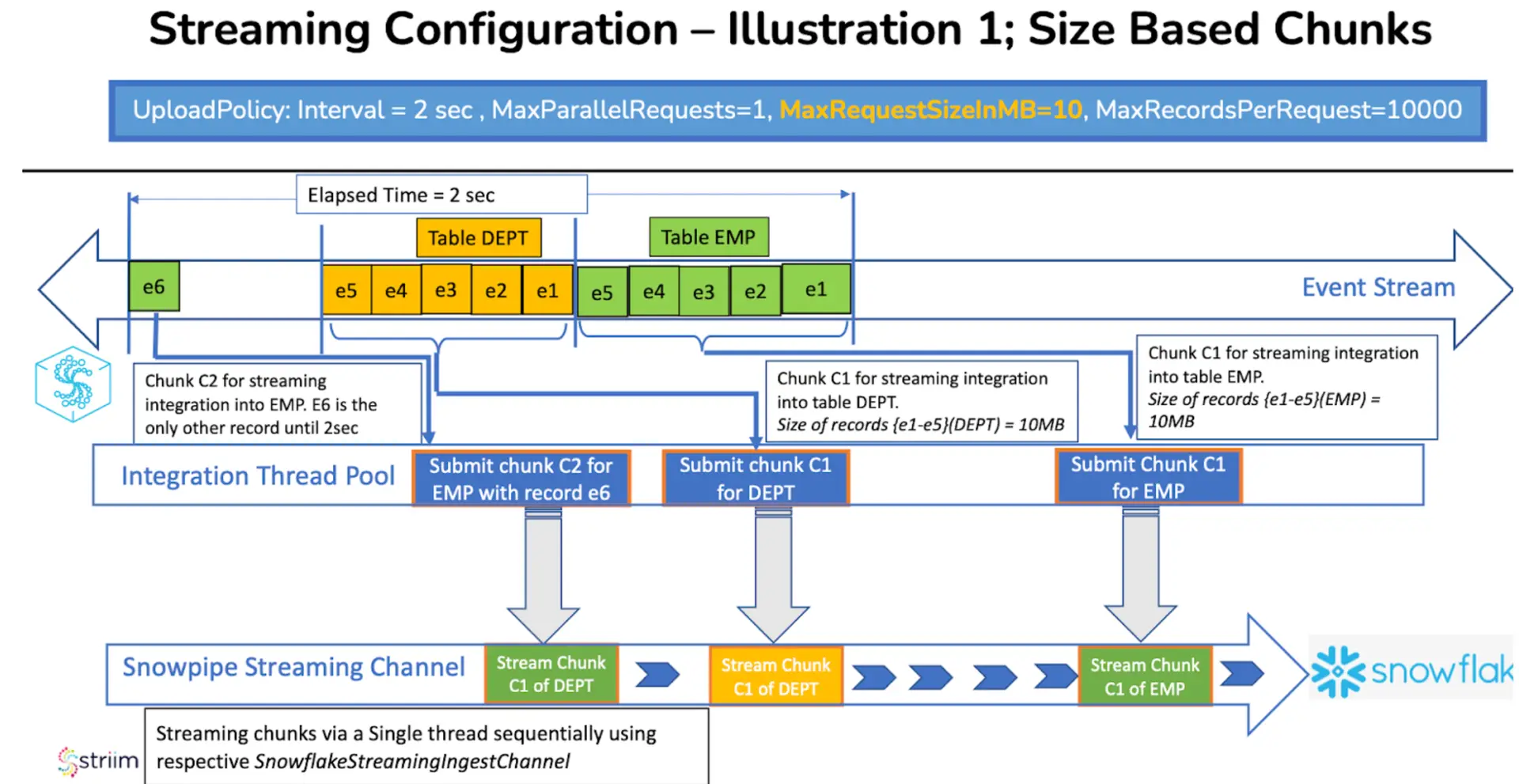
Illustration of Streaming Configuration Interaction:
Consider an example where the UploadPolicy is set to Interval=2sec, and the streaming configuration is set to (MaxParallelRequests=1, MaxRequestSizeInMB=10, MaxRecordsPerRequest=10000). In this scenario, as records flow into the event stream, streaming chunks are created as soon as either 10MB of data has been accumulated or 10,000 records have entered the stream, depending on which condition is satisfied first by the incoming stream of events. Any events that remain outside these parameters and have arrived within 2 seconds before the expiry of the UploadPolicy interval are packed into another streaming chunk.
Real-world application and what customers are saying
The practical application of Striim’s Snowpipe Streaming integration can be seen in the experiences of joint customers like Ciena. Their global head of Enterprise Data & Analytics reported significant satisfaction with Striim’s capabilities in handling large-scale, real-time data events, emphasizing the platform’s scalability and reliability.
Conclusion and Exploring Further
Striim’s data integration capabilities for Snowflake, encompassing both file-based uploads and advanced streaming ingest, offer a versatile and powerful solution for diverse data integration needs. The integration with Snowpipe Streaming stands out for its real-time data processing, cost efficiency, and low latency, making it an ideal choice for businesses looking to leverage real-time analytics.
For those interested in a deeper exploration, we provide detailed resources, including a comprehensive eBook on Snowflake ingest optimization and a self-service, free tier of Striim, allowing you to dive right in with your own workloads!


