










In today’s Whiteboard Wednesday video, Steve Wilkes, founder and CTO of Striim, looks at what you need to consider when evaluating streaming data integration platforms. Read on, or watch the 15-minute video:
We’ve already gone through what the components of a streaming integration platform are. Today we’re going to talk about how you go about evaluating streaming data integration platforms based on these components.
Just to reiterate, you need the platform to be able to:
- Do real-time continuous data collection
- Move that data continuously from where it’s collected to where it’s going
- Support delivery to all the different targets that you care about
- Process the data as it’s moving, so stream processing
- This all needs to be enterprise grade so that it is scalable and reliable, and all those other things that you care about for mission-critical data
- Get insights and alerts on that data movement
Let’s think about the things that you need to consider in order to actually achieve this when you’re evaluating such platforms.
Data Collection & Delivery
For data collection and delivery, you care about quite a few different things. Firstly, it needs to be low latency. If it’s a streaming data integration platform, then just doing bulk loads or micro batch may not be sufficient. You want to be able to collect the data the instant it’s created, within milliseconds typically. You need low-latency data collection.
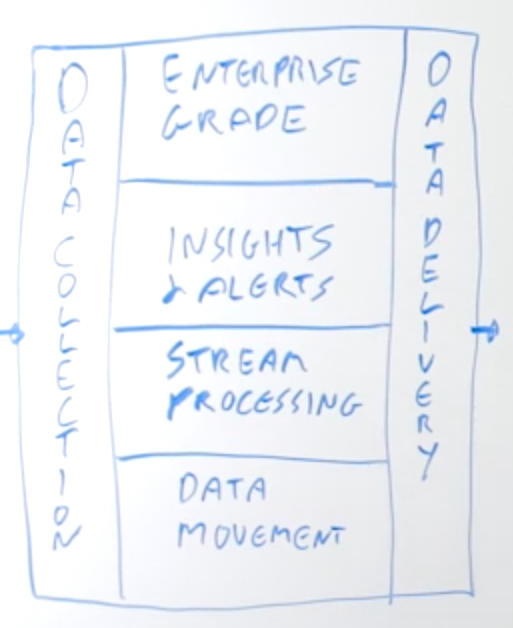 It needs to be able to support all the sources that you care about. If you’re looking for a streaming integration platform, then you’re thinking of more than just one use case. You’re thinking “what platform is going to support all of the streaming data integration needs within my organization?” Supporting just one data source or a couple of data sources isn’t enough.
It needs to be able to support all the sources that you care about. If you’re looking for a streaming integration platform, then you’re thinking of more than just one use case. You’re thinking “what platform is going to support all of the streaming data integration needs within my organization?” Supporting just one data source or a couple of data sources isn’t enough.
You need to be able to support all the sources that you care about now and may care about in the future. That could be databases, files, or messaging systems. It could even be IoT. So think about that when you’re evaluating whether the platform has all the sources that you need. Think about how it can deal with those sources in a number of different ways.
For databases, you may need to be able to do bulk loads into a streaming infrastructure, as well as doing Change Data Capture. This is important for collecting real-time change as it’s happening in a database, the inserts, updates, and deletes. For files, you may need to do bulk files, files that exist already, but also files as they’re created, streaming out the data as it’s being written. Supporting both bulk and change data is equally important.
You also need to consider whether the adapters are actually part of the platform or are they third party. If they are part of the platform and the platform is built well, then it means that they will be able to handle all the different requirements of the platform – scalability, reliability, and recoverability. All of those things are integrated end to end because the adapters are part of the platform.
If they’re third party, then that may not be the case. If you have to plug in third party components into your infrastructure, then you can have areas of brittleness where things may not work properly or problematic interfaces when things change. Try to avoid third party adapters wherever you can.
Data collection and data delivery need to be able to support the end to end recovery and reliability that is part of being enterprise grade. That means that from a database perspective, for example, you may need to be able to support maintaining a database transaction context from one end to the other. You need to be able to pick up from where you left off and make sure that data that is collected is delivered to all of the appropriate targets. These could be variable and different.
You might be delivering some data on-premise and some data to the cloud, but you still need to be able to make sure that all the data has made it there. You need to be able to validate that the data is being written to all the different sources and targets that the platform is supporting.
If it’s part of a platform and they’re not third party, you would expect that to be there. If they are third party, then you have to investigate whether all of those things are supported. Data collection and data delivery is the first part of how you evaluate the platform.
Data Movement
The next part is how does it do data movement? This is crucial to maintaining the kind of high throughput and low latency that you’d expect. Data movement is a number of different things. It’s between processing steps. Between your source collection and your data delivery.
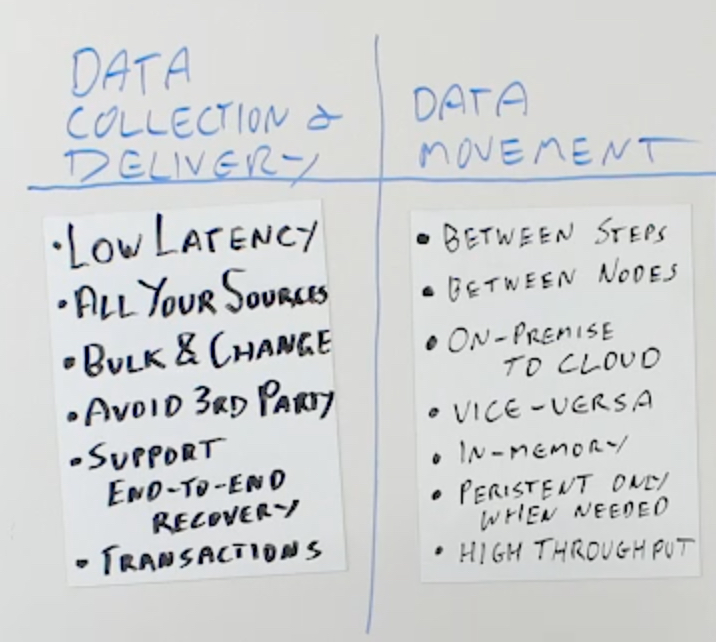 Between source collection, maybe some in-memory processing or maybe some enrichment and data delivery. Or it could be an even a more complex pipeline with multiple steps in it. You’re moving data between each step.
Between source collection, maybe some in-memory processing or maybe some enrichment and data delivery. Or it could be an even a more complex pipeline with multiple steps in it. You’re moving data between each step.
It’s also between nodes. If you have a clustered platform and that platform is moving data between nodes for different processing steps, or maybe between source and target because the target is closer to one of the nodes than other nodes. You need to be able to ensure that the data movement happens efficiently, with high throughput and low latency, between nodes.
You also need to be able to support collecting data on-premise and delivering it into cloud environments, or collecting it from cloud environments and delivering it to on-premise, or moving between clouds. Supporting all these different typologies is all part of data movement.
Ideally as much of the data movement as possible should be in memory only. Try to avoid having to write to disk or do any kind of IO in between processing steps. The reason for this is that each processing step needs to perform optimally in order to get high throughput.
If you are persisting data, that can add latency. Ideally when you’re doing multiple processing steps in a pipeline, you’re doing all of that data movement in memory only, between the steps or just between nodes. You’re not persisting to disk.
You should only use persistent data movement or persistent data streams where needed. There are a couple of really good use cases for this. One is if you have data sources that you can’t rewind into for recoverability, you may want to use a persistent data stream as the first step in the process, but everything downstream can be in memory only.
If you’re collecting data in real time, but you have multiple applications all running at their own speeds against that data, you may want to think about having persistent data streams between different steps. Typically, you want to minimize the amount of persistent data streams that you have and use in-memory only data streams wherever possible. That will really aid in reducing your latency and increasing your throughput.
Stream Processing
The next thing that you need to be able to do is stream processing. Stream processing obviously has to be able to support all of the different types of processing that you want to do. For example, it needs to be able to support complex transformations. If it doesn’t support the transformations that you want, you should be able to add in your own components or your own user defined functions to do the transformations.
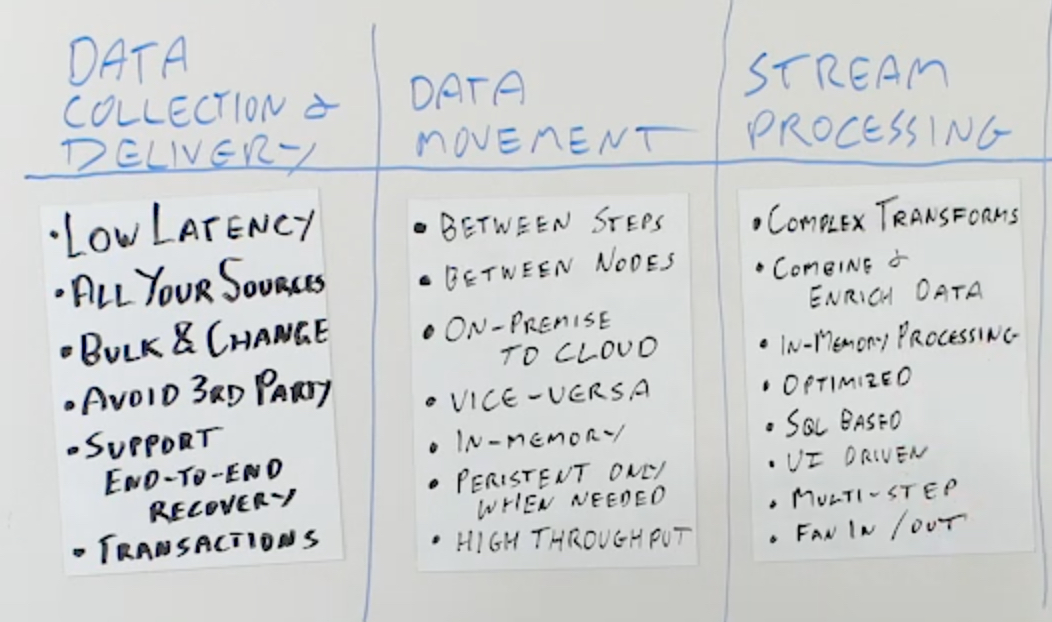 It needs to be able to combine and enrich data. This requires a lot of different constructs for stream processing. When you are combining data together from multiple data streams, they run at high speed and typically events aren’t going to happen at the same time.
It needs to be able to combine and enrich data. This requires a lot of different constructs for stream processing. When you are combining data together from multiple data streams, they run at high speed and typically events aren’t going to happen at the same time.
You need a flexible windowing structure that can maintain a set of events from different data streams to combine together, in order to be able to produce a combined output stream that has the last data from every stream apart from the current data from the current one.
When you’re enriching data, you need to be able to join streaming data with reference data. You can’t go back to a database or go back to the original source of the reference data for every event on a data stream. It’s just too slow. You need to be able to load, cache, and remember the data you are using for enrichment in memory so you can join it really efficiently, in order to keep and maintain the throughput that you’re looking for from the overall system.
You want the stream processing to be optimized. It should really run as fast as if you’d written it yourself manually. It also needs to be easy to use. We recommend that you look for SQL-based stream processing because SQL is the language of data. There are very few people that work with data that don’t understand SQL. It allows you to do filtering, transformation, and data enrichment through natural SQL constructs.
Obviously if you want to do more complex things, you should also be allowed to import your own transformations and work with those. For SQL-based transformations, it enables anyone that knows data to be able to build and understand what the transformations are. You also want building pipelines to be as easily accessible as possible to all the people that want to work with the data.
You need to have a good UI for building the data pipelines and have as much of the process as possible automated through wizards and other UI based assistance. You need to be able to build multi-step stream processing, not just a single source into single target or a single source into single piece of processing into single target. Potentially with fan in and fan out. Multiple data sources coming in, going into multiple processing steps in a staged environment, where they go step by step by step, to potentially multiple targets coming out at the other end.
This all needs to be coordinated, well-maintained, and deployable across a cluster in order to be scalable. Your stream processing should be very rich, very capable, and also very high throughput.
Enterprise Grade
You also need to think about the enterprise-grade qualities of the platform. I’ve mentioned before, for it to be enterprise grade it needs to be scalable. You need to be able to handle increasing the throughput, increasing the number of sources, increasing the number of targets, and increasing the volume of data being generated from each one of those.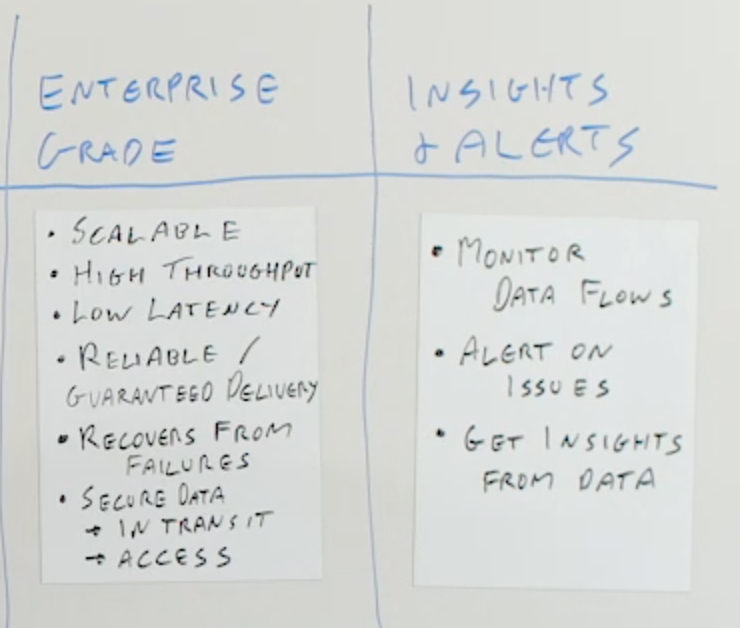
When you’re evaluating platforms and evaluating for a production scenario, you should test the platform with a reasonable throughput that corresponds to what you’re expecting in order to see how it behaves and how it scales, and measure the throughput and the latency from end to end as you’re evaluating the platform.
You also need it to be reliable. You need to be able to ensure that you have guaranteed delivery from source all the way to target. Even if something fails, if a network fails, if the source or the target goes down, if any of the processing nodes in the cluster go down or the whole cluster goes down, you need to be able to ensure that it picks up from where it left off and doesn’t miss any messages.
It has to be able to recover from failures as well. Guaranteed delivery in the normal “I’m always running” case so you don’t miss any messages, just because they disappeared into the ether somewhere. But also, that if you have a failure, you should recover and not lose any messages, not lose any events that come from the source into the target.
Of course, security is also paramount. You can secure the data while it’s moving in transit, so it’s encrypted as it goes across the network. But also that you can secure who has access to the data, who can work with individual data streams, who can see the data on individual data streams, who can build applications, who can view the results of building applications.
You need security that works across the whole end to end and deals with every single component, so that you can secure them and lock them down and make sure that only the people that need to work with data, can.
Insights & Alerts
Finally, you need to make sure that the platform gives you visibility into your data, that you can monitor the data flows and see what’s going on in real time, that you get alerts when anything happens. This could be when CPU or memory usage on any of the nodes goes above certain criteria. It could be when applications crash, or data flows crash. It could be when volume goes above or below what you expect, and doing that in a granular fashion. For example, when an individual database table goes above or below what you expect.
You need to be able to work with insights into the data flows that help you operationalize this and make sure that it’s working full time, 24/7, when you actually put it into production. You may even want to get insights on the data itself, drill down into the actual data that’s flowing, and do some analytics on that. If your streaming integration platform can also give you those valuable insights on the streaming data, then that’s the icing on the cake.
Just to summarize, when you’re evaluating streaming data integration platforms, you need to make sure that the platform can do everything that you need, to get your data from where it’s generated to where it needs to be, in order to get real value out of your data.
To learn more about streaming data integration, please visit our Real-time Data Integration solution page, schedule a demo with a Striim expert, or download the Striim platform to get started.



