










In this blog post, we’re going to take a look at how you can use the Striim platform to move real-time data to Cloudera from a variety of sources.
The Striim platform provides an enterprise-grade streaming integration solution for moving real-time change data from a wide variety of sources to Cloudera distributions of Apache Kafka, Apache Kudu, and Apache Hadoop, without impacting source systems. With support for hybrid IT infrastructures, Striim complements Cloudera solutions by enabling organizations to use full breadth and depth of their data in real time in order to gain a complete and up-to-date view into their operations.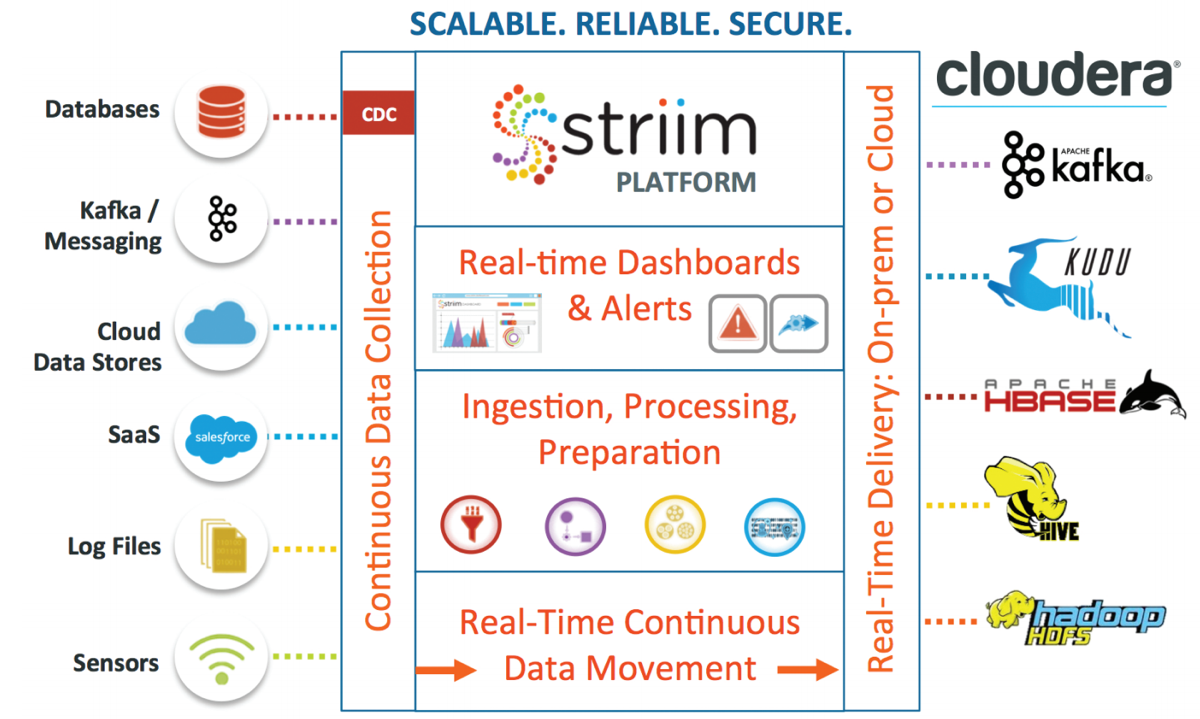
Benefits
- Ingest real-time data into CDK (Kafka), Kudu, Hadoop with low impact
- Continuously collect data from databases, logs, messaging, sensors, and more
- Process data in-flight without extensive coding
- Get immediate insights and alerts
- Use low-latency data in Cloudera for operational decision making
Why Striim?
- Real-time data integration from a wide variety of data sources
- Designed for high-volume, high-velocity data
- Non-intrusive CDC from databases with event guarantees
- Built-in security, scalability, and reliability
- In-flight enrichment via built-in cache
- Quick to deploy via SQL-like queries and wizards-based UI
Non-intrusive, Real-time Data Ingestion
The Striim platform continuously ingests real-time data from a variety of sources out-of-the-box – including databases, cloud applications, files, message queues, and devices – on-premises or in the cloud. For enterprise databases such as Oracle, SQL Server, MySQL, HPE NonStop, and MariaDB, the platform offers non-intrusive change data capture (CDC) to minimize the impact on source systems. Striim supports major data formats, including JSON, XML, AVRO, delimited binary, free text, and change records.
With a drag-and-drop UI and wizards, Striim simplifies creating data flows from popular sources to move data to Cloudera solutions including CDK (Kafka), Hadoop, HBase, Hive, and Kudu. The data can be delivered “as-is,” or be put through a series of in-flight transformations and enrichments. By using real-time, pre-processed data – especially in Kudu, Impala, and Kafka – customers can rapidly gain timely, operational intelligence from their Cloudera applications.
Delivery to Cloudera, On-premises or Cloud
The Striim platform can continuously apply pre-processed, streaming data to Cloudera solutions with sub-second latency. With parallelization capabilities, Striim offers optimized loading to Cloudera solutions. Striim can also deliver real-time data to other targets such as databases and files.
Built-in Stream Processing and Monitoring
Through SQL-based continuous queries, the Striim platform filters, aggregates, transforms, joins, and enriches multiple streams of real-time data in-memory to rapidly prepare the data for different downstream users before delivering to Cloudera environments. 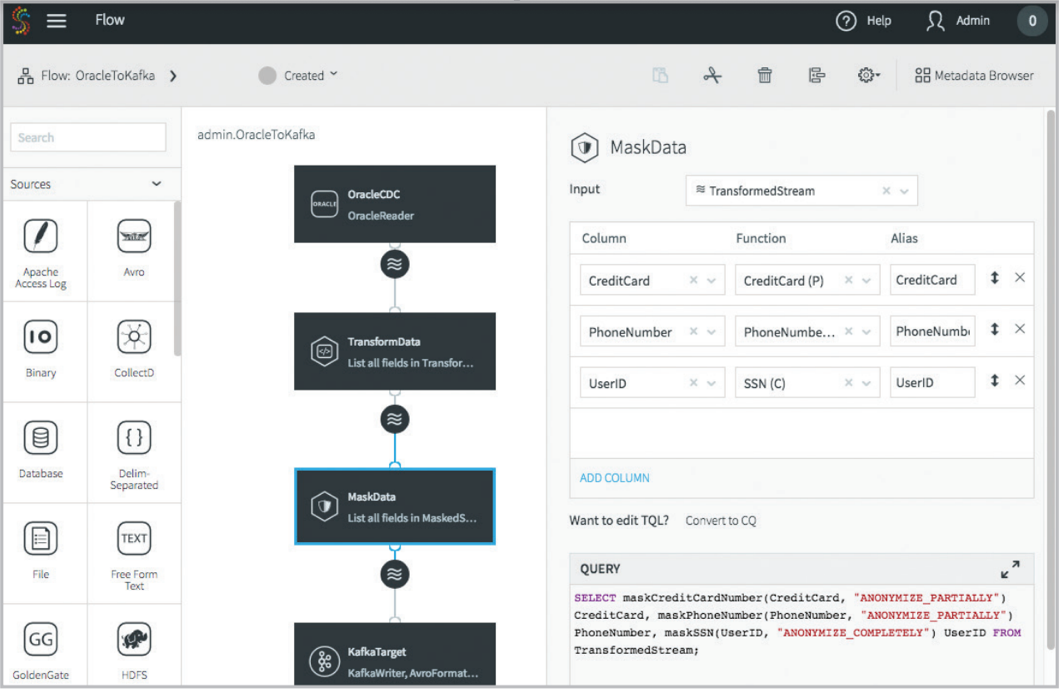
Striim also comes with built-in validation and monitoring capabilities. The platform enables users to continuously monitor the health of the data pipelines via real-time dashboards and alerts.
Enterprise-grade Modern Streaming Integration
Striim is designed form the ground up to support high-volume, high velocity data with built-in validation, security, high-availability, reliability, and scalability to support mission-critical applications.
Unlike traditional ETL solutions, Striim continuously ingests granular and larger data sets for richer analytics. It does so without impacting source systems, and processes the data in-memory, while it is streaming, to enable sub-second latency. Striim also differs from traditional logical replication tools with its optimized support for a wide range of data types, data sources, and targets, and its out-of-the-box comprehensive stream processing capabilities.
To learn more about how you can utilize the Striim platform to move data to Cloudera, please reach out to schedule a demo with a Striim expert or download the platform and try it for yourself.



