










Adopting the Google Cloud Platform for real-time scaling, analytics or machine learning is important to your business, and as such, your approach to Google cloud data centers on real-time data movement. In this post, I will delve into why real-time data movement, change data capture, and stream processing are necessary parts of this process.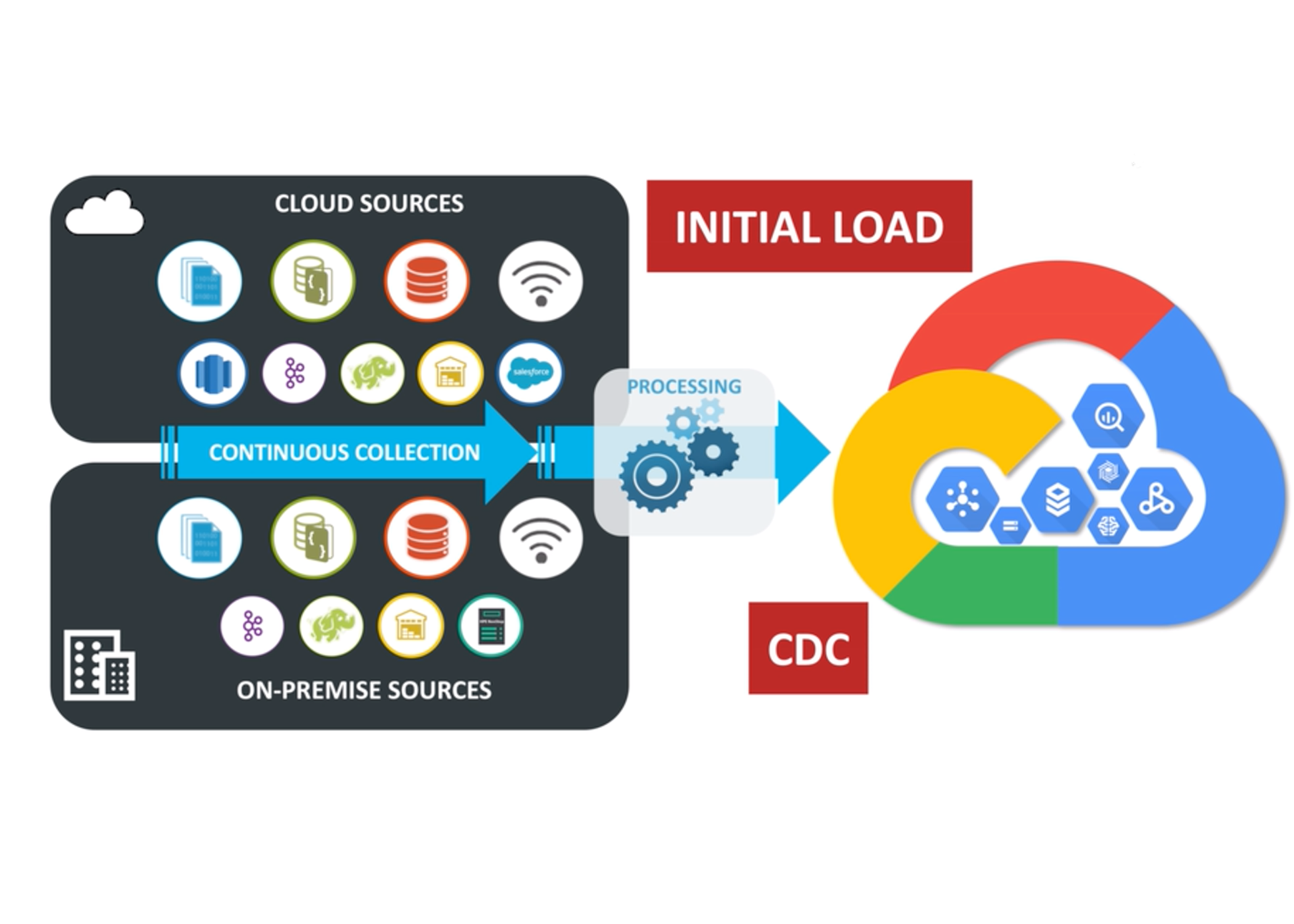
You’ve already decided that you want to adopt the Google Cloud Platform. This could be Google BigQuery, Cloud Pub/Sub, Cloud SQL, Cloud DataProc, or any number of other technologies.
You may want to migrate existing applications to the cloud, scale elastically as necessary, or use the cloud for analytics or machine learning, but running applications in the cloud, as VMs or containers, is only part of the problem. You also need to consider how to you move data to the cloud, ensure your applications or analytics are always up to date, and make sure the data is in the right format to be valuable.
The most important starting point is ensuring that your Google cloud data centers on real-time movement. Batch data movement can cause unpredictable load on cloud targets, and has a high latency, meaning your data is often hours old. For modern applications, having up-to-the-second information is essential, for example, to provide current customer information, accurate business reporting, or for real-time decision making.

Streaming data from on-premise to the Google Cloud Platform requires making use of appropriate data collection technologies. For databases, this is change data capture, or CDC, which directly and continuously intercepts database activity, and collects all the inserts, updates, and deletes as events, as they happen. Log data requires file tailing, which reads at the end of one or more files across potentially multiple machines, and streams the latest records as they are written. Other sources like IoT data or third-party SaaS applications also require specific treatment in order to ensure data can be streamed in real time.
Once you have streaming data, the next consideration is what processing is necessary to make the data valuable for your specific Google Cloud destination, and this depends on the use case.
For database migration or elastic scalability use cases, where the target schemas is similar to the source, moving raw change data from on-premises databases to Google Cloud SQL may be sufficient. However, for real-time applications sourcing from Google Cloud Pub/Sub, or analytics use cases built on Google BigQuery or Cloud DataProc, it may be necessary to perform stream processing before the data is delivered to the cloud. This processing can transform the data structure, and enrich it with additional context information, while the data is in-flight, adding value to the data and optimizing downstream analytics.
Striim’s streaming integration platform can continuously collect data from on-premises sources, or other cloud databases, and deliver to all of your Google Cloud Platform endpoints. Striim can take care of initial loads, as well as CDC for the continuous application of change, and these data flows can be created rapidly, and monitored and validated continuously through our intuitive UI. With Striim, your cloud migrations, scaling, and analytics can be built and iterated on at the speed of your business, ensuring your data is always where you want it, when you want it.
To learn more about how Google cloud data centers on real-time movement, visit our Striim for Google Cloud Platform page, schedule a demo with a Striim expert, or provision Striim in the Google Cloud Marketplace and try it for yourself.




