










Additional new Striim features focus on the ease of use and extensibility of the platform. Continuing from our discussion in Part 1, please read on to learn of several other new features designed to enhance manageability and productivity.
Ease-of-Use Enhancements
Apache Kafka integration has been a prevalent use case for many Striim customers for connecting enterprise databases and other sources with SQL-based stream processing. In these releases, we focus on its ease of use, and introduce support for Schema Registry to help Striim users easily track and store schema evolution and increase developer productivity.
We added the Continuous Data Processing Validation feature to enable Striim users to continuously monitor the behavior of data pipelines using pre-built, real-time dashboards.
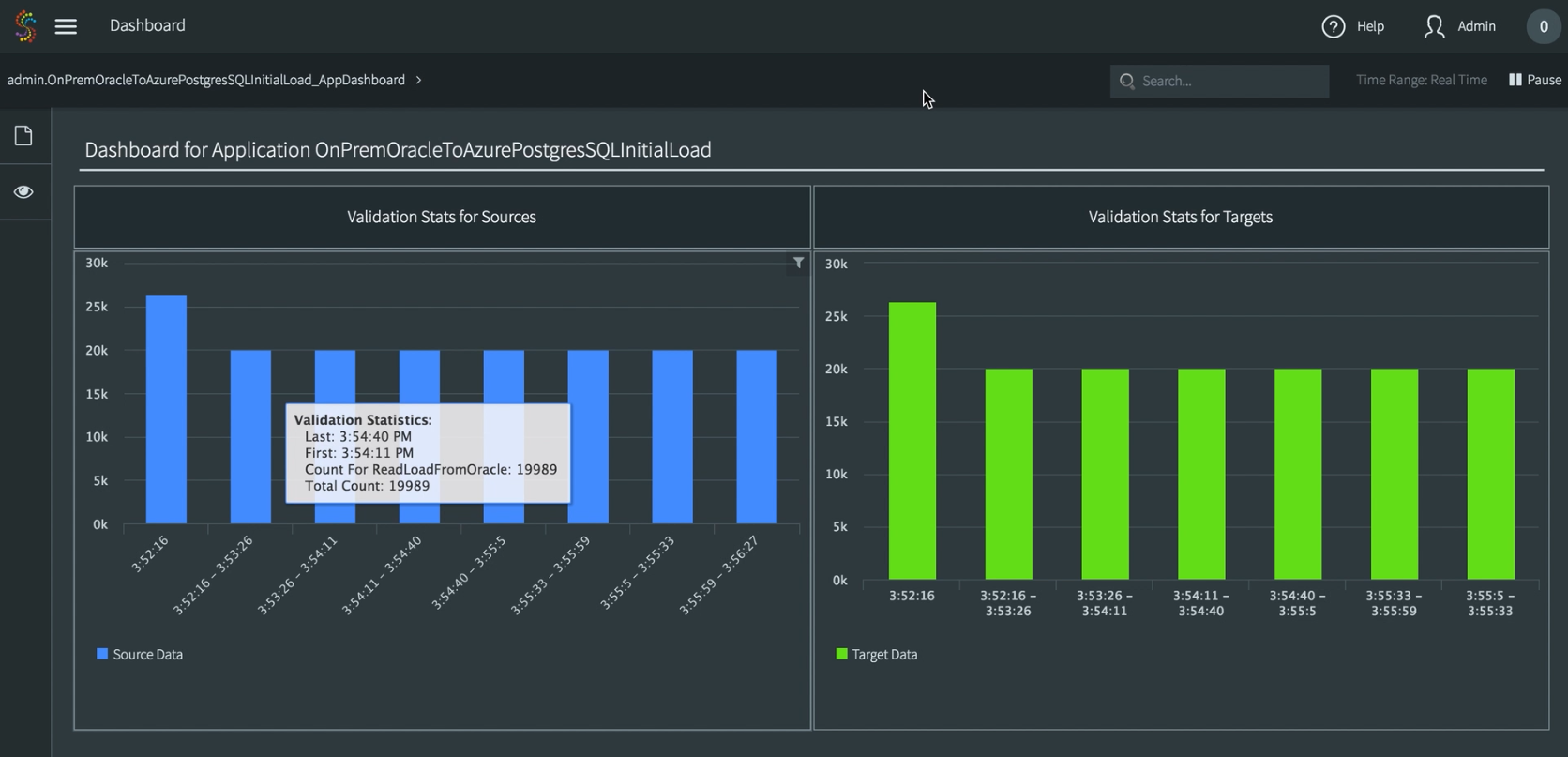
This new feature allows you to easily trace in real time whether, and to what degree, the data ingested completed the required processing steps. While enhancing the ease of use of the platform, this granular processing validation capability makes Striim an excellent fit for mission-critical environments that require event-by-event tracking of stream processing.
Striim 3.8.4 brought improved metadata management capabilities, as well. In addition to existing FLM (file lineage metadata) capabilities, Striim introduced FLM extensions for Oracle Database. Striim now allows users to more easily query and perform impact analysis when working with the Oracle database as a source to support operational simplicity.
Striim 3.8.4 also introduced the Event Table component, which enables you to easily join data-in-motion with dynamically changing reference data to provide context for end users as needed. Event tables work similar to a cache and can be loaded from a source to instantiate. Unlike the cache, event tables are continuously updated with the changes occurring in the source and also support in place deletes. Striim’s continuous queries can both insert into, and select from, an event table. With these relational semantics, Event Tables enable flexible use cases that require real time updates within the platform for data enrichment, and context.
Greater Extensibility
For increased extensibility, we added the Open Processor feature. This new open platform component allows end users to bring any code they have written into the Striim platform. It’s particularly useful when you have pre-existing machine learning (ML) models, e.g., using R, and want to quickly bring the algorithms into Striim to extend its application logic. It is directly accessible via the UI for you to operationalize your existing models via real-time integration and processing.
Expanding the list of supported sources and targets is an ongoing theme for our releases. In addition to above-mentioned cloud services, Striim now supports real-time data delivery to a popular NoSQL platform Apache Cassandra. Cassandra users can now perform analytics using up-to-date data including enterprise databases, log files, messaging systems, Hadoop, and sensor data. We also added a new data source: JMX. The new JMX Reader allows Striim users to collect, process, analyze, and deliver real-time statistics and status information from Java apps and services. Now Striim can consume any metric published in JMX by a Java application, and support new use cases, such as performance monitoring for Kafka, via real-time dashboards.
Thank you for reviewing this overview of the latest releases of Striim. Please do not hesitate to contact us to schedule a demo, or experience Striim v3.8.5 by downloading the Striim platform.



