If you’re reading this, there’s a chance you need to send real-time data from SQL Server for cloud migration, operational reporting or agentic AI. How hard can it be?
The answer lies in the transition. Capturing changes isn’t difficult in and of itself; it’s the act of doing so at scale without destabilizing your production environment. While SQL Server provides native Change Data Capture (CDC) functionality, making it reliable, efficient, and low-impact in a modern hybrid-cloud architecture can be challenging. If you’re looking for a clear breakdown of what SQL Server CDC is, how it works, and how to build a faster, more scalable capture strategy, you’re in the right place. This guide will cover the methods, the common challenges, and the modern tooling required to get it right.
What is SQL Server Change Data Capture (CDC)?
Change Data Capture (CDC) is a technology that identifies and records row-level changes—INSERTs, UPDATEs, and DELETEs—in SQL Server tables. It captures these changes as they happen and makes them available for downstream systems, all without requiring modifications to the source application’s tables. This capability enables businesses to feed live analytics dashboards, execute zero-downtime cloud migrations, and maintain audit trails for compliance. In today’s economy, businesses can no longer tolerate the delays of nightly or even hourly batch jobs. Real-time visibility is essential for fast, data-driven decisions. At a high level, SQL Server’s native CDC works by reading the transaction log and storing change information in dedicated system tables. While this built-in functionality provides a starting point, scaling it reliably across a complex hybrid or cloud architecture requires a clear strategy and, often, specialized tooling to manage performance and operational overhead.
Where SQL Server CDC Fits in the Modern Data Stack
Change Data Capture should not be considered an isolated feature, but a critical puzzle piece within a company’s data architecture. It functions as the real-time “on-ramp” that connects transactional systems (like SQL Server) to the cloud-native and hybrid platforms that power modern business. CDC is the foundational technology for a wide range of critical use cases, including:
- Real-time Analytics: Continuously feeding cloud data warehouses (like Snowflake, BigQuery, or Databricks) and data lakes to power live, operational dashboards.
- Cloud & Hybrid Replication: Enabling zero-downtime migrations to the cloud or synchronizing data between on-premises systems and multiple cloud environments.
- Data-in-Motion AI: Powering streaming applications and AI models with live data for real-time predictions, anomaly detection, and decisioning.
- Microservices & Caching: Replicating data to distributed caches or event-driven microservices to ensure data consistency and high performance.
How SQL Server Natively Handles Change Data Capture
SQL Server provides built-in CDC features (available in Standard, Enterprise, and Developer editions) that users must enable on a per-table basis. Once enabled, the native process relies on several key components:
- The Transaction Log: This is where SQL Server first records all database transactions. The native CDC process asynchronously scans this log to find changes related to tracked tables.
- Capture Job (sys.sp_cdc_scan): A SQL Server Agent job that reads the log, identifies the changes, and writes them to…
- Change Tables: For each tracked source table, SQL Server creates a corresponding “shadow table” (e.g., cdc.dbo_MyTable_CT) to store the actual change data (the what, where, and when) along with metadata.
- Log Sequence Numbers (LSNs): These are used to mark the start and end points of transactions, ensuring changes are processed in the correct order.
Cleanup Job (sys.sp_cdc_cleanup_job): Another SQL Server Agent job that runs periodically to purge old data from the change tables based on a user-defined retention policy.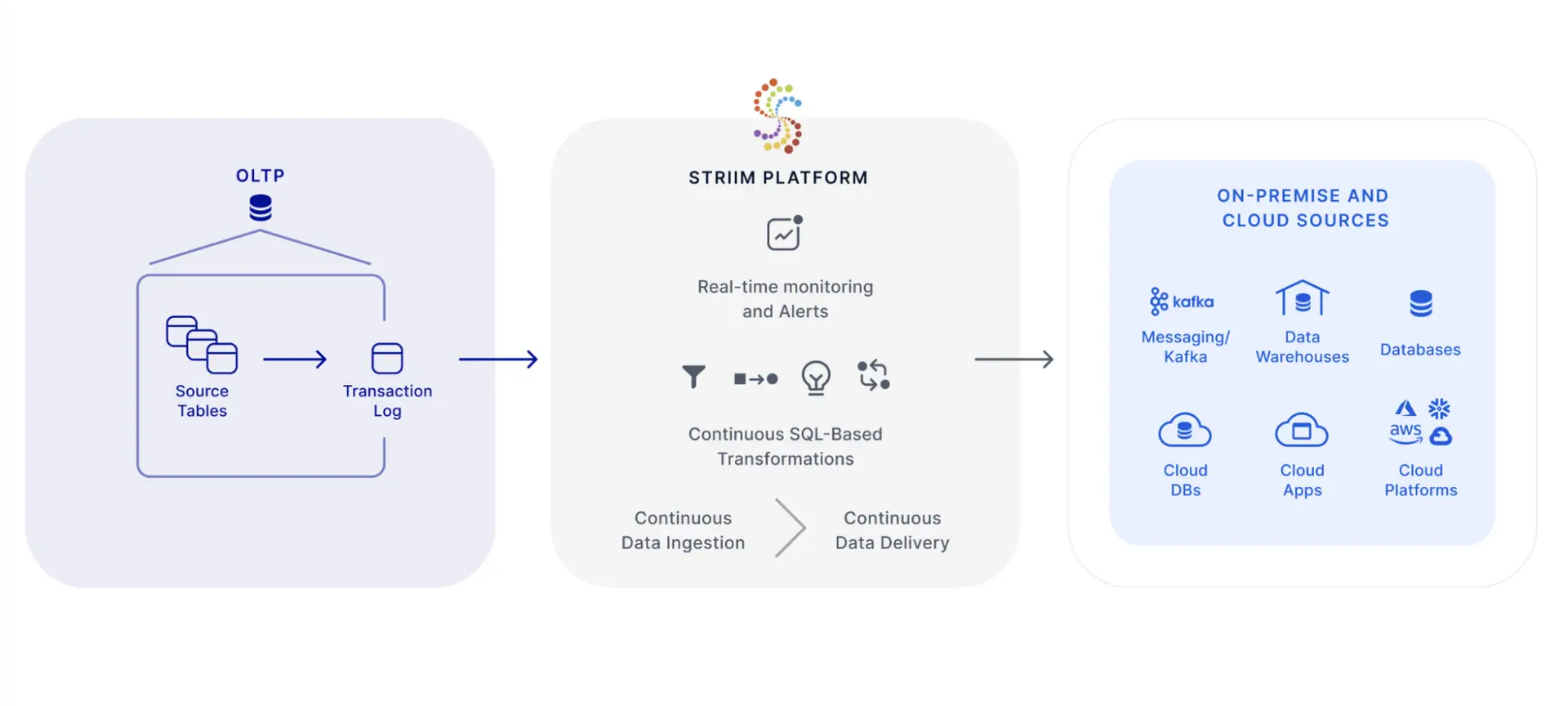 While this native system offers a basic form of CDC, it was not designed for the high-volume, low-latency demands of modern cloud architectures. The SQL Server Agent jobs and the constant writing to change tables introduce performance overhead (added I/O and CPU) that can directly impact your production database, especially at scale.
While this native system offers a basic form of CDC, it was not designed for the high-volume, low-latency demands of modern cloud architectures. The SQL Server Agent jobs and the constant writing to change tables introduce performance overhead (added I/O and CPU) that can directly impact your production database, especially at scale.
How Striim MSJET Handles SQL Server Change Data Capture
Striim’s MSJET provides high-performance, log-based CDC for SQL Server without relying on triggers or shadow tables. Unlike native CDC, it eliminates the overhead of SQL Server Agent jobs and intermediate change tables. The MSJET process relies on several key components:
- The Transaction Log: MSJET reads directly from SQL Server’s transaction log—including via fn_dblog—to capture all committed INSERT, UPDATE, and DELETE operations in real time.
- Log Sequence Numbers (LSNs): MSJET tracks LSNs to ensure changes are processed in order, preserving transactional integrity and exactly-once delivery.
- Pipeline Processing: As changes are read from the log, MSJET can filter, transform, enrich, and mask data in-flight before writing to downstream targets.
- Schema Change Detection: MSJET automatically handles schema modifications such as new columns or altered data types, keeping pipelines resilient without downtime.
- Checkpointing and Retention: MSJET internally tracks log positions and manages retention, without relying on SQL Server’s capture or cleanup jobs, which consume disk space, I/O, and CPU resources.
Key Advantage: Because MSJET does not depend on shadow tables or SQL Server Agent jobs, it avoids the performance overhead, storage consumption, and complexity associated with native CDC. This enables high-throughput, low-latency CDC suitable for enterprise-scale, real-time streaming to cloud platforms such as Snowflake, BigQuery, Databricks, and Kafka.
Common Methods for Capturing Change Data from SQL Server
SQL Server provides several methods for capturing change data, each with different trade-offs in performance, latency, operational complexity, and scalability. Choosing the right approach is essential to achieve real-time data movement without overloading the source system.
| Method | Performance Impact | Latency | Operational Complexity | Scalability |
|---|---|---|---|---|
| Polling-Based | High | High (Minutes) | Low | Low |
| Trigger-Based | Very High | Low | High | Low |
| Log-Based | Very Low | Low (Seconds/Sub-second) | Moderate to Low | High |
Polling-Based Change Capture
- How it works: The polling method periodically queries source tables to detect changes (for example, SELECT * FROM MyTable WHERE LastModified > ?). This approach is simple to implement but relies on repetitive full or incremental scans of the data.
- The downside: Polling is highly resource-intensive, putting load on the production database with frequent, heavy queries. It introduces significant latency, is never truly real-time, and often fails to capture intermediate updates or DELETE operations without complex custom logic.
- The Striim advantage: Striim eliminates the inefficiencies of polling by capturing changes directly from the transaction log. This log-based approach ensures every insert, update, and delete is captured in real time with minimal source impact—delivering reliable, low-latency data streaming at scale.
Trigger-Based Change Capture
- How it works: This approach uses database triggers (DML triggers) that fire on every INSERT, UPDATE, or DELETE operation. Each trigger writes the change details into a separate “history” or “log” table for downstream processing.
- The downside: Trigger-based CDC is intrusive and inefficient. Because triggers execute as part of the original transaction, they increase write latency and can quickly become a performance bottleneck—especially under heavy workloads. Triggers also add development and maintenance complexity, and are prone to breaking when schema changes occur.
- The Striim advantage: Striim completely avoids trigger-based mechanisms. By capturing changes directly from the transaction log, Striim delivers a non-intrusive, high-performance solution that preserves source system performance while providing scalable, real-time data capture.
Shadow Table (Native SQL CDC)
- How it works: SQL Server’s native Change Data Capture (CDC) feature uses background jobs to read committed transactions from the transaction log and store change information in system-managed “shadow” tables. These tables record before-and-after values for each change, allowing downstream tools to query them periodically for new data.
- The downside: While less intrusive than triggers, native CDC still introduces overhead on the source system due to the creation and maintenance of shadow tables. Managing retention policies, cleanup jobs, and access permissions adds operational complexity. Latency is also higher compared to direct log reading, and native CDC often struggles to scale efficiently for high-volume workloads.
- The Striim advantage: Striim supports native SQL CDC for environments where it’s already enabled, but it also offers a superior alternative through its MSJET log-based reader. MSJET delivers the same data with lower latency, higher throughput, and minimal operational overhead—ideal for real-time, large-scale data integration.
Log-Based (MSJET)
How it works:
Striim’s MSJET reader captures change data directly from SQL Server’s transaction log, bypassing the need for triggers or shadow tables. This approach reads the same committed transactions that SQL Server uses for recovery, ensuring every INSERT, UPDATE, and DELETE is captured accurately and in order.
The downside:
Implementing log-based CDC natively can be complex, as it requires a deep understanding of SQL Server’s transaction log internals and careful management of log sequence numbers and recovery processes. However, when done right, it provides the most accurate and efficient form of change data capture.
The Striim advantage:
MSJET offers high performance, low impact, and exceptional scalability—supporting CDC rates of up to 150+ GB per hour while maintaining sub-second latency. It also automatically handles DDL changes, ensuring continuous, reliable data capture without manual intervention. This makes MSJET the most efficient and enterprise-ready option for SQL Server change data streaming.
Challenges of Managing Change Data Capture at Scale
Log-based CDC is the gold standard for accuracy and performance, but managing it at enterprise scale introduces new operational challenges. As data volumes, change rates, and schema complexity grow, homegrown or basic CDC solutions often reach their limits, impacting reliability, performance, and maintainability.
Handling Schema Changes and Schema Drift
- The pain point: Source schemas evolve constantly—new columns are added, data types change, or fields are deprecated. These “schema drift” events often break pipelines, cause ingestion errors, and lead to downtime or data inconsistency.
- Striim’s advantage: Built with flexibility in mind, Striim’s MSJET engine automatically detects schema changes in real time and propagates them downstream without interruption. Whether the target needs a structural update or a format transformation, MSJET applies these adjustments dynamically, maintaining full data continuity with zero downtime.
Performance Overhead and System Impact
- The pain point: Even SQL Server’s native log-based CDC introduces operational overhead. Its capture and cleanup jobs consume CPU, I/O, and storage, while writing to change tables can further slow down production workloads.
- When it becomes critical: As transaction volumes surge or during peak business hours, this additional load can impact response times and force trade-offs between production performance and data freshness.
- Striim’s advantage: MSJET is engineered for high performance and low impact. By reading directly from the transaction log without relying on SQL Server’s capture or cleanup jobs, it minimizes system load while sustaining throughput of 150+ GB/hour. All CDC processing occurs within Striim’s distributed, scalable runtime, protecting your production SQL Server from performance degradation.
Retention, Cleanup, and Managing CDC Metadata
- The pain point: Native CDC requires manual maintenance of change tables, including periodic cleanup jobs to prevent unbounded growth. Misconfigured or failed jobs can lead to bloated tables, wasted storage, and degraded query performance.
- Striim’s advantage: MSJET removes this burden entirely. It manages retention, checkpointing, and log positions internally, no SQL Server Agent jobs, no cleanup scripts, no risk of data buildup. Striim tracks its place in the transaction log independently, ensuring reliability and simplicity at scale.
Security, Governance, and Audit Considerations
- The pain point: Change data often includes sensitive information, such as PII, financial records, or health data. Replicating this data across hybrid or multi-cloud environments can introduce significant security, compliance, and privacy risks if not properly managed.
- Striim’s advantage: Striim provides a comprehensive, enterprise-grade data governance framework. Its Sherlock agent automatically detects sensitive data, while Sentinel masks, tags, and encrypts it in motion to enforce strict compliance. Beyond security, Striim enables role-based access control (RBAC), filtering, data enrichment, and transformation within the pipeline—ensuring only the data that is required is written to downstream targets. Combined with end-to-end audit logging, these capabilities give organizations full visibility, control, and protection over their change data streams.
Accelerate and Simplify SQL Server CDC with Striim
Relying on native SQL Server CDC tools or DIY pipelines comes with significant challenges: performance bottlenecks, brittle pipelines, schema drift, and complex maintenance. These approaches were not built for real-time, hybrid-cloud environments, and scaling them often leads to delays, errors, and operational headaches. Striim is purpose-built to overcome these challenges. It is an enterprise-grade platform that delivers high-performance, log-based CDC for SQL Server, combining reliability, simplicity, and scalability. With Striim, you can:
- Capture data with minimal impact: MSJET reads directly from the transaction log, providing real-time change data capture without affecting production performance.
- Handle schema evolution automatically: Detect and propagate schema changes in real time with zero downtime, eliminating a major source of pipeline failure.
- Process data in-flight: Use a familiar SQL-based language to filter, transform, enrich, and mask sensitive data before it reaches downstream systems.
- Enforce security and governance: Leverage Sherlock to detect sensitive data and Sentinel to mask, tag, and encrypt it in motion. Combined with RBAC, filtering, and audit logging, you maintain full control and compliance.
- Guarantee exactly-once delivery: Ensure data integrity when streaming to cloud platforms like Snowflake, Databricks, BigQuery, and Kafka.
- Unify integration and analytics: Combine CDC with real-time analytics to build a single, scalable platform for data streaming, processing, and insights.
Stop letting the complexity of data replication slow your business. With Striim, SQL Server CDC is faster, simpler, and fully enterprise-ready. Interested in a personalized walkthrough of Striim’s SQL Server CDC functionality? Please schedule a demo with one of our CDC experts! Alternatively you can try Striim for free.


