Getting started
This topic describes Validata Platform, a self-managed high-performance data validation platform that verifies consistency between source and target data systems during replication, migrations, analytics operations, and AI workloads. For a summary of Validata features and capabilities, see Product summary. To create your first validation, see Build your first validation.
If you want to use Validata Cloud, the fully-managed SaaS version of Validata, you can get started with the documentation here.
What is Validata?
Validata is a high-performance data validation platform that verifies consistency between source and target data systems during replication, migrations, analytics operations, and AI workloads. Validata can compare datasets across homogeneous and heterogeneous datasets to identify and classify data discrepancies enabling organizations to reduce operational risk, enhance governance by supporting internal business policies and regulatory compliance, and ensure that accurate and trusted data flows to downstream analytics and AI pipelines.
Validata operates as a standalone platform and integrates with any replication engine or data movement solution. The system compares datasets at scale with minimal load on operational databases, using a configurable set of validation methods that support full-dataset, partial-dataset, and custom SQL-based checks. Validata produces detailed discrepancy reports, historical run logs, and reconciliation scripts to help users correct out-of-sync data efficiently.
Organizations use Validata to enhance operational reliability and governance programs, support cloud modernization initiatives, and complement their data and AI feature pipelines. Validata provides end-to-end visibility into data accuracy during and after system transitions, enabling faster cutovers, improved audit readiness, and higher trust in enterprise data.
Conceptual overview
When replicating or migrating data between systems, ensuring that the target dataset remains consistent with the source is critical. Validata is a standalone data validation platform designed to work alongside any replication or data movement tool. It allows you to verify, report, and reconcile data integrity across environments without requiring changes to your existing data pipelines.
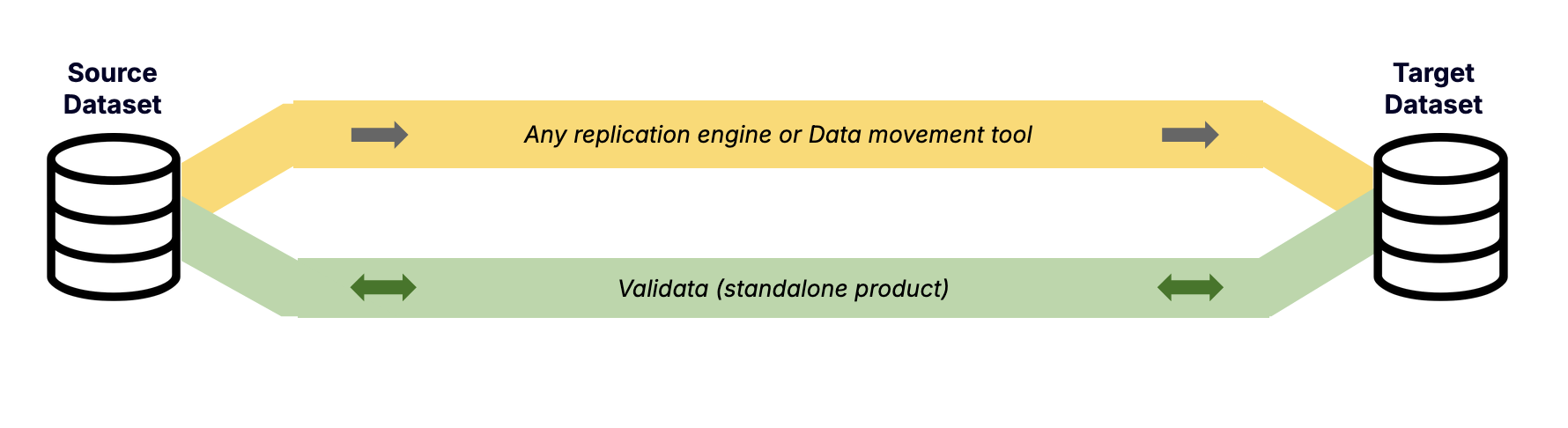
The diagram above illustrates how Validata integrates into a typical data architecture.
The Replication Layer (Yellow Path): This represents your data transfer layer, where tools such as Striim or any other replication system moves data from source to target.
The Validation Layer (Green Path): This represents Validata. It connects directly to both the source and target systems to analyze data independently of the replication process.
By operating independently, Validata provides an objective assurance layer. It ensures that data transferring from operational databases to cloud data warehouses is precise and in sync. It also provides specific measures to handle complex scenarios, such as replicated data containing mismatched, duplicate, missing, extra or null-key records.
Validata performance
Real-time validation and repair engine: Validata is a real-time engine designed to run alongside high-volume production transaction processing. The architecture combines several strategies to optimize performance and throughput: minimizing load on source and target databases, using multi-threaded and parallel comparison processing on the Validata Server, and supporting custom SQL queries when you require specialized comparisons.
Managed impact on sources and targets: Based on the validation method you choose, data or a signature of the data can be captured from source and target servers, and then all comparison processing can be performed on a separate Validata Server. This architecture enables Validata to run concurrently with little impact on production resources.
Automated parallelization: In the Validata Server, all comparison processing is multi-threaded, cached, and executed within the scalable architecture. The result is fast comparisons of extremely large and active tables.
Comparison optimization: The Validata Server uses specialized comparison algorithms and in-memory processing to perform validations independently of database query workloads and other network activity. The architecture supports use cases where data changes occur faster than comparisons can be performed. Validata queues these requests and processes them as fast as resources are available. As a result, comparison requests are queued and processed reliably, even when data changes occur faster than they can be evaluated.
Key capabilities
Validata enables you to create automated validation workflows that run continuously or on-demand. Its core capabilities include:
Flexible validation methods: Select from six distinct built-in validation methods—ranging from full-dataset comparisons to lightweight key checks to a custom-validation method—based on your dataset size and type, reporting requirements, and infrastructure capabilities of your data systems and Validata server.
Detailed reporting: If mismatches are detected, Validata generates detailed reports accessible within and downloadable from the UI. These reports identify exactly which tables, records, or columns are out of sync.
Automated reconciliation: Validata generates reconciliation SQL scripts that you can execute to quickly correct out-of-sync data in the target environment.
Scheduled verification: You can schedule validation jobs to run at regular intervals (for example, hourly or daily) for ongoing, automated data quality verification.
Use cases
Validata supports a wide range of enterprise scenarios where data accuracy, consistency, and trust are essential. Its validation, reporting, and reconciliation capabilities provide assurance across operational systems, governance processes, and modern AI/ML data pipelines that downstream applications and teams are working on trusted data.
Operational data reliability
Enterprises depend on consistent and trustworthy data to power day-to-day operations. Validata strengthens reliability across replication, migration, and synchronization workflows by independently verifying that data has been transferred correctly between systems.
Typical challenges addressed include:
Data loss or duplication during replication.
Corrupted records caused by system interruptions.
Incomplete or inconsistent datasets after migration.
Silent failures in change data capture or ETL pipelines.
By validating each dataset end-to-end and surfacing discrepancies early, Validata helps engineering and operations teams maintain consistent, production-ready data across environments. Run-level reports, reconciliation scripts for mismatched datasets, and historical tracking provide the clarity needed to identify and resolve issues before they affect applications or analytics.
Governance, compliance, and business policy assurance
Organizations often need to demonstrate not only that data pipelines function correctly, but that they comply with internal policies, external regulations, and audit requirements. Validata provides a structured framework that helps teams enforce these standards consistently by scheduling comprehensive validation schemes and retaining the report results.
Key value areas include:
Policy enforcement and data accuracy: Validata confirms that every record expected in the target exists and matches the source. This ensures data integrity standards defined by business policies are met across operational and analytical systems.
Regulatory and audit readiness: The Validata configurations and run history provide evidence of data quality controls. Each validation run generates detailed historical records containing timestamps, discrepancy summaries, and corrective actions. These reports serve as verifiable evidence for internal audits, regulatory reviews, and broader governance processes.
Traceability and lineage verification: Validata maintains traceability from source to target by verifying that the data lineage implied by your replication and transformation processes is accurate. This reduces risks arising from unintended data loss, unauthorized changes, or unrecorded modifications.
Together, these capabilities help organizations demonstrate that their data movement processes meet both operational and compliance-oriented expectations—without requiring manual inspections or point-in-time checks.
AI/ML data quality and model assurance
Machine learning and AI systems depend heavily on the accuracy, completeness, and stability of the datasets used to train and evaluate models. Validata extends its validation framework to these workflows, helping teams build models on trustworthy data.
Training dataset integrity: Validata verifies that training datasets in downstream environments match the approved source version, reducing the risk of degraded or unreproducible model performance.
Prevention of data drift and silent corruption: By identifying missing, mismatched, or duplicated records, Validata helps prevent issues that commonly affect AI/ML pipelines, such as silent data drift, incomplete training samples, or biases introduced through corrupted records.
Support for AI governance and model compliance: Retention of historical validation reports provides traceable evidence of dataset integrity over time. This supports emerging AI governance frameworks that require:
Transparency into dataset origin and composition.
Evidence of data quality controls.
Reproducibility and auditability of training data.
Validata ensures that the data used for AI/ML development is accurate, complete, and traceable—strengthening confidence in the models built on top of it for data science, MLOps, and compliance teams alike.