Striim concepts
Striim's key concepts include applications, flows, sources, streams, Kafka-persisted streams, types, events, windows, continuous queries (CQs), caches, WActions and WActionStores, targets, and subscriptions.
Tungsten Query Language (TQL) and applications
Striim lets you develop and run custom applications that acquire data from external sources, process it, and deliver it for consumption through the Striim dashboard or to other applications. As in a SQL environment, the core of every application is one or more queries. As detailed in the rest of this Concepts Guide, an application also contains sources, targets, and other logical components organized into one or more flows, plus definitions for any charts, maps, or other built-in visualizations it uses.
Applications may be created graphically using the web client or coded using the Tungsten Query Language (TQL), a SQL-like language that can be extended with Java (see Sample applications for programmers for examples). TQL is also used by the Tungsten console, the platform's command-line client.
Flow
Flows define what data an application receives, how it processes the data, and what it does with the results.
Flows are made up of several kinds of components:
sources to receive real-time event data from adapters
streams to define the flow of data among the other components
windows to bound the event data by time or count
continuous queries to filter, aggregate, join, enrich, and transform the data
caches of historical, or reference data to enrich the event data
WActionStores to populate the built-in reports and visualizations and persist the processed data
targets to pass data to external applications
An application may contain multiple flows to organize the components into logical groups. See MultiLogApp for an example.
An application is itself a flow that can contain other flows, so when an application contains only a single flow, it does not need to be explicitly created. See PosApp for an example.
Source
A source is a start point of a flow and defines how data is acquired from an external data source. A flow may have multiple sources.
Each source specifies:
an input adapter (reader) for collection of real-time data from external sources such as database tables or log files (for more detailed information, see Sources)
properties required by the selected reader, such as a host name, directory path, authentication credentials, and so on
with some readers, a parser that defines what to do with the data from the source (for example, DSVParser to parse delimited files, or FreeFormTextParser to parse using regex)
an output stream to pass the data to other flow components
Here is the TQL code for one of the sources in the MultiLogApp sample application:
CREATE SOURCE Log4JSource USING FileReader (
directory:'Samples/MultiLogApp/appData',
wildcard:'log4jLog.xml',
positionByEOF:false
)
PARSE USING XMLParser(
rootnode:'/log4j:event',
columnlist:'log4j:event/@timestamp,
log4j:event/@level,
log4j:event/log4j:message,
log4j:event/log4j:throwable,
log4j:event/log4j:locationInfo/@class,
log4j:event/log4j:locationInfo/@method,
log4j:event/log4j:locationInfo/@file,
log4j:event/log4j:locationInfo/@line'
)
OUTPUT TO RawXMLStream;Log4JSource uses the FileReader adapter to read …/Striim/Samples/MultiLogApp/appData/log4jLog.xml, parses it with XMLParser, and outputs the data to RawXMLStream. In the UI, the same source looks like this:
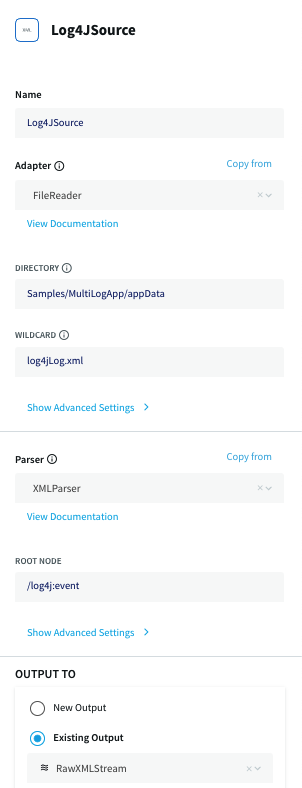
Note: The other examples in the Concepts Guide appear in their TQL form only, but they all have UI counterparts similar to the above.
Stream
A stream passes one component’s output to one or more other components. For example, a simple flow that only writes to a file might have this sequence:
source > stream1 > queryA > stream2 > FileWriter
This more complex flow branches at stream2 in order to send alerts and populate the dashboard:
source > stream1 > queryA > stream2 > ... ... stream2 > queryB > stream3 > Subscription ... stream2 > queryC > WActionStore
Kafka-persisted streams
Striim natively integrates Apache Kafka, a high-throughput, low-latency, massively scalable message broker. For a technical explanation, see kafka.apache.org.
In simple terms, what Kafka offers Striim users is the ability to persist real-time streaming source data to disk at the same time Striim loads it into memory, then replay it later. If data comes in too fast to be handled by the built-in Kafka broker, an external Kafka system may be used instead, and scaled up as necessary.
Replaying from Kafka has many potential uses. For example:
If you put a source persisted to a Kafka stream in one application and the associated CQs, windows, caches, targets, and WActionStores in another, you can bring down the second application to update the code, and when you restart it processing of source data will automatically continue from the point it left off, with zero data loss and no duplicates.
Developers can use a persisted stream to do A/B testing of various TQL application options, or to perform any other useful experiments.
You can perform forensics on historical data, mining a persisted stream for data you didn't know would be useful. For example, if you were troubleshooting a security alert, you could write new queries against a persisted stream to gather additional data that was not captured in a WActionStore.
By persisting sources to an external Kafka broker, you can enable zero-data-loss recovery after a Striim cluster failure for sources that are normally not recoverable, such as HTTPReader, TCPReader, and UDPReader (see Recovering applications).
Persisting to an external Kafka broker can also allow recovery of sources running on a remote host using the Forwarding Agent.
You can use a Kafka stream like any other stream, by referencing it in a CQ, putting a window over it, and so on. Alternatively, you can also use it as a Kafka topic:
You can read the Kafka topic with KafkaReader, allowing events to be consumed later using messaging semantics rather than immediately using event semantics.
You can read the Kafka topic with an external Kafka consumer, allowing development of custom applications or integration with third-party Kafka consumers.
For additional information, see:
Type
A stream is associated with a Striim data model type, a type being a named set of fields, each of which has a name and a Java data type, such as Integer or String (see Supported data types for a full list). Any other Java type may be imported and used, though with some restrictions, for example regarding serializability. One field may have a key for use in generating WActions.
A stream that receives its input from a source is automatically assigned the Striim type associated with the reader specified in the source. For other streams, you must create an appropriate Striim type. Any casting or other manipulation of fields is performed by queries.
Here is sample TQL code for a Striim type suitable for product order data:
CREATE TYPE OrderType( storeId String KEY, orderId String, sku String, orderAmount Double, dateTime DateTime );
Each event of this type will have the ID of the store where it was purchased, the order ID, the SKU of the product, the amount of the order, and the timestamp of the order.
Striim also has a number of predefined types:
AvroEvent: see Avro Parser
CollectdEvent: see Collectd Parser
JsonNodeEvent: see JSON Parser
ParquetEvent: see Parquet Parser
StriimParserEvent: see Striim Parser
WAEvent: for an introduction, see Sample applications for programmers; see also WAEvent contents for change data. HP NonStop reader WAEvent fields, MySQL Reader WAEvent fields, Oracle Reader and OJet WAEvent fields, PostgreSQL Reader WAEvent fields, SQL Server readers WAEvent fields
XMLNodeEvent: see XML Parser V2
See also JSON Parser for discussion of user-defined JSON types.
Event
A stream is composed of a series of events, much as a table in a SQL environment is composed of rows. Each event is a fixed sequence of data elements corresponding to the stream's type.
Window
A Window represents a bounded view onto a stream of data, containing zero or more consecutive events which can be treated as a batch by downstream components. CQ aggregate functions perform work on batches of data from windows, allowing applications to evaluate groups of events instead of being limited to acting on individual events.
The bounds of a window can be defined in several ways:
Event count (for example, 10,000 events)
Real time (for example, five minutes of time elapsed on the clock)
Data time based on a timestamp field (for example, five minutes of time according to that timestamp)
A combination of time and count (for example, every 5 seconds or 500 events, which keeps windows from growing stale)
Striim supports three types of windows: sliding, jumping, and session. Windows send data to downstream queries when their contents change (sliding) or expire (jumping), or when there has been a gap in use activity (session).
Sliding windows always contain the most recent events in the data stream. For example, at 8:06 am, a five-minute sliding window would contain data from 8:01 to 8:06, at 8:07 am, it would contain data from 8:02 am to 8:07 am, and so on. The time values may be taken from an attribute of the incoming stream (see the ON dateTime example below).
If the window's size is specified as a number of events, each time a new event is received, the oldest event is discarded.
If the size is specified as a length of time, each event is discarded after the specified time has elapsed since it was added to the window, so the number of events in the window may vary. Be sure to keep this in mind when writing queries that make calculations.
If both a number of events and a length of time are specified, each event is discarded after it has been in the window for the specified time, or sooner if necessary to avoid exceeding the specified number.
Jumping windows are periodically updated with an entirely new set of events. For example, a five-minute jumping window would output data sets for 8:00:00-8:04:59 am, 8:05:00-8:09:59 am, and so on. A 10,000-event jumping window would output a new data set for every 10,000 events. If both five minutes and 10,000 events were specified, the window would output a new data set every time it accumulates 10,000 events or five minutes has elapsed since the previous data set was output.
To put it another way, a jumping window slices the data stream into chunks. The query, WActionStore, or target that receives the events will process each chunk in turn. For example, a map visualization for a five-minute jumping window would refresh every five minutes.
For better performance, filter out any unneeded fields using a query before the data is sent to the window.
This window breaks the RetailOrders stream (discussed above) into chunks:
CREATE JUMPING WINDOW ProductData_15MIN
OVER RetailOrders
KEEP WITHIN 15 MINUTE ON dateTime;Each chunk contains 15 minutes worth of events, with the 15 minutes measured using the timestamp values from the events' dateTime field (rather than the Striim host's system clock).
The PARTITION BY field_name option applies the KEEP clause separately for each value of the specified field. For example, this window would contain 100 orders per store:
CREATE JUMPING WINDOW Orders100PerStore OVER RetailOrders KEEP 100 ROWS PARTITION BY storeId;
Session windows break a stream up into chunks when there are gaps in the flow of events; that is, when no new event has been received for a specified period of time (the idle timeout). Session windows are defined by user activity, and represent a period of activity followed by a defined gap of inactivity. For example, this window has a defined inactivity gap of ten minutes, as shown in IDLE TIMEOUT. If a new order event arrives after ten minutes have passed, then a new session is created.
CREATE SESSION WINDOW NewOrders OVER RetailOrders IDLE TIMEOUT 10 MINUTE PARTITION BY storeId;
For more information about window syntax, see CREATE WINDOW.
Continuous query (CQ)
Most of an application’s logic is specified by continuous queries. Striim queries are in most respects similar to SQL, except that they are continually running and act on real-time data instead of relational tables.
Queries may be used to filter, aggregate, join, enrich, and transform events. A query may have multiple input streams to combine data from multiple sources, windows, caches, and/or WActionStores.
Some example queries illustrating common use cases:
Filtering events
The GetErrors query, from the MultiLogApp sample application, filters the log file data in Log4ErrorWarningStream to pass only error messages to ErrorStream:
CREATE CQ GetErrors INSERT INTO ErrorStream SELECT log4j FROM Log4ErrorWarningStream log4j WHERE log4j.level = 'ERROR';
Warning messages are discarded.
Filtering fields
The TrackCompanyApiDetail query, also from the MultiLogApp sample application, inserts a subset of the fields in a stream into a WActionStore:
CREATE CQ TrackCompanyApiDetail INSERT INTO CompanyApiActivity(company,companyZip,companyLat,companyLong,state,ts) SELECT company,companyZip,companyLat,companyLong,state,ts FROM CompanyApiUsageStream;
Values for the fields not inserted by TrackCompanyApiDetail are picked up from the most recent insertion by TrackCompanyApiSummary with the same company value.
Alerting
CREATE CQ SendErrorAlerts INSERT INTO ErrorAlertStream SELECT 'ErrorAlert', ''+logTime, 'error', 'raise', 'Error in log ' + message FROM ErrorStream;
The SendErrorAlerts query, from the MultiLogApp sample application, sends an alert whenever an error message appears in ErrorStream.
Aggregation
This portion of the GenerateMerchantTxRateOnly query, from the PosApp sample application, aggregates the data from the incoming PosData5Minutes stream and outputs one event per merchant per five-minute batch of transactions to MerchantTxRateOnlyStream:
CREATE CQ GenerateMerchantTxRateOnly
INSERT INTO MerchantTxRateOnlyStream
SELECT p.merchantId,
FIRST(p.zip),
FIRST(p.dateTime),
COUNT(p.merchantId),
SUM(p.amount) ...
FROM PosData5Minutes p ...
GROUP BY p.merchantId;
Each output event includes the zip code and timestamp of the first transaction, the total number of transactions in the batch, and the total amount of those transactions.
Enrichment
The GetUserDetails query, from the MultiLogApp sample application, enhances the event log message events in InfoStream by joining the corresponding user and company names and zip codes from the MLogUserLookup cache:
CREATE CQ GetUserDetails INSERT INTO ApiEnrichedStream SELECT a.userId, a.api, a.sobject, a.logTime, u.userName, u.company, u.userZip, u.companyZip FROM InfoStream a, MLogUserLookup u WHERE a.userId = u.userId;
A subsequent query further enhances the data with latitude and longitude values corresponding to the zip codes, and uses the result to populate maps on the dashboard.
Handling nulls
The following will return values from the stream when there is no match for the join in the cache:
SELECT ... FROM stream S LEFT OUTER JOIN cache C ON S.joinkey=C.joinkey WHERE C.joinkey IS NULL
Cache
A memory-based cache of non-real-time historical or reference data acquired from an external source, such as a static file of postal codes and geographic data used to display data on dashboard maps, or a database table containing historical averages used to determine when to send alerts. If the source is updated regularly, the cache can be set to refresh the data at an appropriate interval.
Cached data is typically used by queries to enrich real-time data by, for example, adding detailed user or company information, or adding latitude and longitude values so the data can be plotted on a map. For example, the following query, from the PosApp sample application, enriches real-time data that has previously been filtered and aggregated with company name and location information from two separate caches, NameLookup and ZipLookup:
CREATE CQ GenerateWactionContext INSERT INTO MerchantActivity SELECT m.merchantId, m.startTime, n.companyName, m.category, m.status, m.count, m.hourlyAve, m.upperLimit, m.lowerLimit, m.zip, z.city, z.state, z.latVal, z.longVal FROM MerchantTxRateWithStatusStream m, NameLookup n, ZipLookup z WHERE m.merchantId = n.merchantId AND m.zip = z.zip LINK SOURCE EVENT;
Note
A cache is loaded into memory when it is deployed, so deployment of an application or flow with a large cache may take some time.
WAction and WActionStore
A WActionStore stores event data from one or more sources based on criteria defined in one or more queries. These events may be related using common key fields. The stored data may be queried by CQs (see CREATE CQ (query)), by dashboard visualizations (see Defining dashboard queries), or manually using the console (see Browsing data with ad-hoc queries). This data may also be directly accessed by external applications using the REST API (see Querying a WActionStore using the REST APInot available in Striim Developer; for information on the Striim Cloud feature, see Querying a WActionStore using the REST API).
A WActionStore may exist only in memory or it may be persisted to disk (see CREATE WACTIONSTORE). If a WActionStore exists only in memory, when the available memory is full, older events will be removed to make room for new ones. If a WActionStore is persisted to disk, older events remain available for use in queries and visualizations and by external applications.
A WAction typically consists of:
detail data for a set of related real-time events (optional)
results of calculations on those events
common context information
For example, a WAction of logins for a user might contain:
source IP, login timestamp, and device type for each login by the user (detail data)
number of logins (calculation)
username and historical average number of logins (context information)
If the number of logins exceeded the historical average by a certain amount, the application could send an alert to the appropriate network administrators.
Including the detail data (by including the LINK SOURCE EVENT option in the query) allows you to drill down in the visualizations to see specific events. If an application does not require that, detail data may be omitted, reducing memory requirements.
See PosApp for a discussion of one example.
Target
A target is an end point of a flow and defines how data is passed to an external application for storage, analysis, or other purposes. A flow may have multiple targets.
Each target specifies:
an input stream
an output adapter (writer) to pass data to an external system such as a database, data warehouse, or cloud storage (for more detailed information, see Targets)
with some adapters, a formatter that defines how to write the data (for example, JSONFormatter or XMLFormattter)
properties required by the selected adapter, such as a host name, directory path, authentication credentials, and so on
See PosApp for a discussion of one example.
Subscription
A subscription sends an alert to specified users by a specified channel.
Each subscription specifies:
an input stream
an alert adapter
properties required by the selected adapter, such as an SMTP server and email address
See Sending alerts from applications for more information.