Iceberg Writer programmer's reference
Iceberg Writer properties
property | type | default value | notes |
|---|---|---|---|
Catalog Connection Profile Name | enum | See Connection profiles and Catalog connection profile properties. | |
Catalog Type | enum | Hadoop | Select the catalog type you are using for Iceberg (see Configure the Iceberg catalog). |
CDDL Action | enum | Process | |
Compute Connection Profile Name | enum | See Connection profiles and Compute connection profile properties. | |
Compute Type | enum | Google Dataproc | Leave set to Google Dataproce (the only type supported in this release). |
Data Lake Connection Profile Name | enum | See Connection profiles and Data Lake connection profile properties. | |
Data Lake Type | enum | GCS | Leave set to GCS (the only type supported in this release). |
Excluded Tables | string | When a wildcard is specified for Tables:'mynamespace.%', ExcludedTables:'mynamespace.ignore' | |
External Stage Connection Profile Name | enum | See Connection profiles and Setting Google Cloud Storage (GCS) connection profile properties. If the External Staging Location folder is in the same project as the data lake folder, leave this blank to use the data lake connection profile. | |
External Staging Location | string | Specify the path to the external stage folder you created as described in Configure Google Cloud Storage (GCS) buckets for Iceberg Writer. The files in this folder will be deleted automatically when Iceberg Writer is stopped. | |
External Staging Type | enum | GCS | Leave set to GCS (the only type supported in this release). |
Iceberg Tables Location | string | Specify the path to the data lake folder you created as described in Configure Google Cloud Storage (GCS) buckets for Iceberg Writer. This folder must already exist when Iceberg Writer is started for the first time and it must be in the GCS instance specified by the Data Lake Connection Profile Name. | |
Mode | enum | APPENDONLY | |
Optimized Merge | Boolean | False | Appears in Flow Designer only when Mode is Merge. Set to True only when Mode is MERGE and the target's input stream is the output of an HP NonStop reader, MySQL Reader, or Oracle Reader source and the source events will include partial records. For example, with Oracle Reader, when supplemental logging has not been enabled for all columns, partial records are sent for updates. When the source events will always include full records, leave this set to False. When Optimized Merge is True, each primary key update is handled in a separate write operation. If the source has frequent primary key updates, this may lead to a decline in write performance compared with Optimized Merge = False. |
Parallel Threads | integer | Supported only when Mode is APPENDONLY. See Creating multiple writer instances (parallel threads). | |
Tables | string | The name(s) of the table(s) to write to, in the format You can provide multiple mappings with a semicolon as a separator. For example: When the input stream of the target is the output of a DatabaseReader, IncrementalBatchReader, or SQL CDC source, it can write to multiple tables. In this case, specify the names of both the source and target tables. You may use the source.emp,target_namespace.emp source_schema.%,target_namespace.% source_database.source_schema.%,target_namespace.% source_database.source_schema.%, target_namespace.% See Mapping columns and Defining relations between source and target using ColumnMap and KeyColumns for additional options. | |
Upload Policy | string | eventcount:100000, interval:60s | The upload policy may include eventcount and/or interval (see Setting output names and rollover / upload policies for syntax). Buffered data is written to the storage account every time any of the specified values is exceeded. With the default value, data will be written every 60 seconds or sooner if the buffer contains 100,000 events. When the app is quiesced, any data remaining in the buffer is written to the storage account; when the app is undeployed, any data remaining in the buffer is discarded. |
Catalog connection profile properties
In this release, supported catalogs are BigLake metastore, Nessie, and Polaris. Hadoop in the same Google Cloud Storage instance as the data lake is also supported as a catalog. This is recommended only for development and testing, as performance may not be adequate for a production environment.
Setting BigLake metastore connection profile properties
In the Create or Edit Connection Profile dialog, select BigLake Metastore as the endpoint type.
Project ID: specify the Google Cloud project ID of the BigLake metastore
Region: specify the region of the BigLake metastore
Setting Nessie connection profile properties
In the Create or Edit Connection Profile dialog, select Nessie as the endpoint type.
Authentication Type: Select Google Open ID if the Nessie server uses OAuth. In that case, provide the Host URI and Nessie Branch Name, then click Sign in using Google Open ID.
If the Nessie server has no authentication mechanism, select None.
If the Nessie server uses some other authentication mechanism, use Additional Configuration to provide the required properties.
Host URI: specify the Nessie REST API endpoint in the format
http[s]://<IP address>:<port>/api/v1Nessie Branch Name: specify the Nessie branch to use for the Iceberg catalog
Additional Configuration: if your Nessie instance requires additional properties (see Nessie client configuration options, click Add Property to add them. For example, if Nessie is configured for OAuth, you would specify something like this:
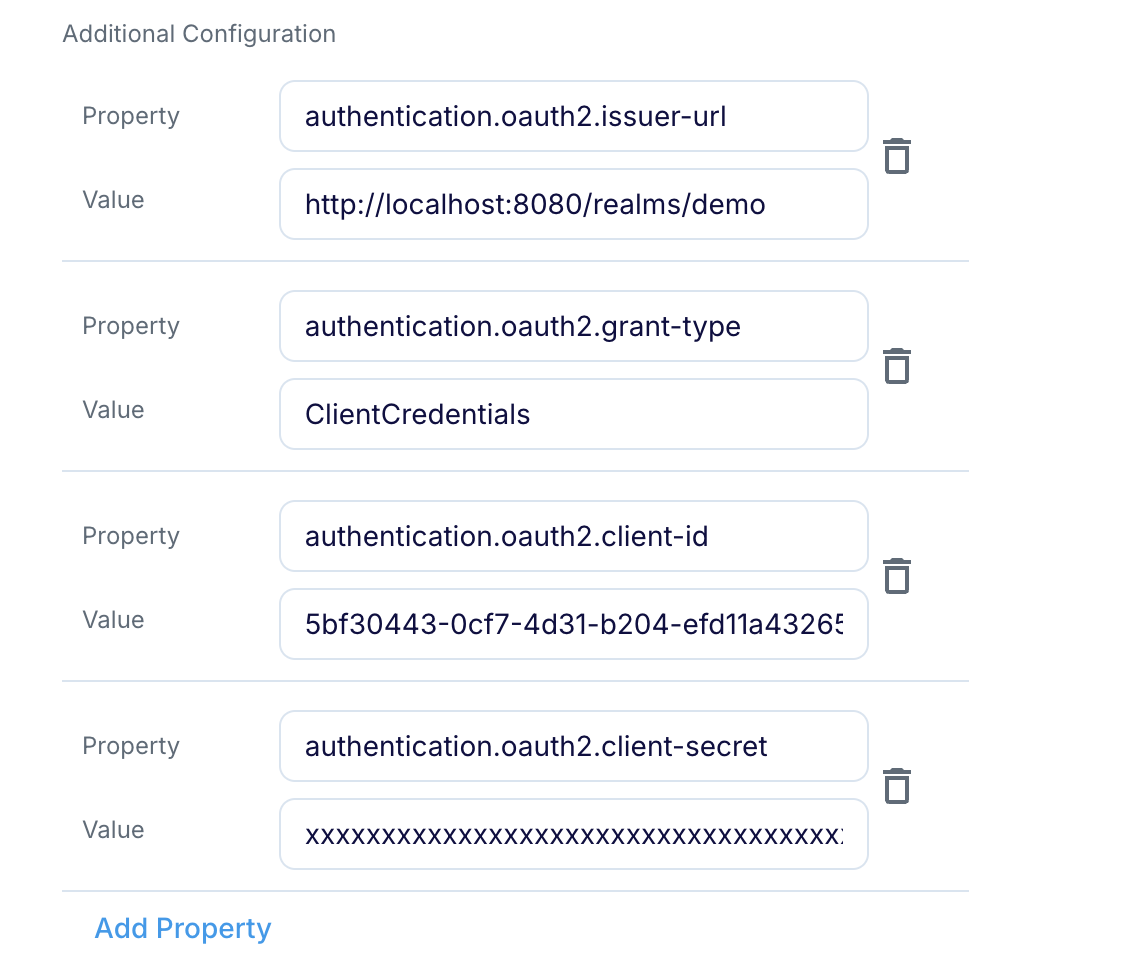
Setting Polaris connection profile properties
In the Create or Edit Connection Profile dialog, select Polaris as the endpoint type.
Host URI: specify the Polaris REST API endpoint in the format
http[s]://<IP address>:<port>/api/catalogCatalog Name: specify the name of the Polaris catalog for Iceberg
Client ID: specify the assigned client identifier
Client Secret: specify the confidential value used to authenticate the client
Additional Configuration: optionally specify Spark configuration properties; for example, to specify the client region:
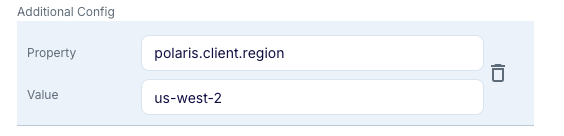
Compute connection profile properties
In this release, the only compute engine supported is Google Dataproc.
Setting Google Dataproc connection profile properties
In the Create or Edit Connection Profile dialog, select Google Dataproc as the endpoint type.
Dataproc Cluster Name: specify the name of the Dataproc cluster you created as instructed in Create a new Dataproc cluster
Project ID: specify the project ID you used when you created the Dataproc cluster as instructed in Create a new Dataproc cluster
Region: specify the region of the Dataproc cluster you created as instructed in Create a new Dataproc cluster
Service Account Key: upload the service account key you downloaded as instructed in Create the service account and download the service account key; alternatively, this field may be left blank and the key path can be set via the environment variable GOOGLE_APPLICATION_CREDENTIALS (Striim must be restarted after setting the environment variable)
Connection Retry: See Client Side Retries > Client Library Retry Concepts
Additional Configuration: optionally specify Spark configuration properties, such as number of Spark executor instances or number of cores per executor, that will override the default Spark configuration
Data Lake connection profile properties
In this release, the only data lake supported is Google Cloud Storage (GCS).
Setting Google Cloud Storage (GCS) connection profile properties
In the Create or Edit Connection Profile dialog, select GCS as the endpoint type.
Project ID: specify the project ID you used when you created the bucket as instructed in Configure Google Cloud Storage (GCS) buckets for Iceberg Writer
Service Account Key: upload the service account key you downloaded as instructed in Create the service account and download the service account key; alternatively, this field may be left blank and the key path can be set via the environment variable GOOGLE_APPLICATION_CREDENTIALS (Striim must be restarted after setting the environment variable)
Connection Retry: optionally adjust this setting (see GCS Writer properties)