What is Striim?
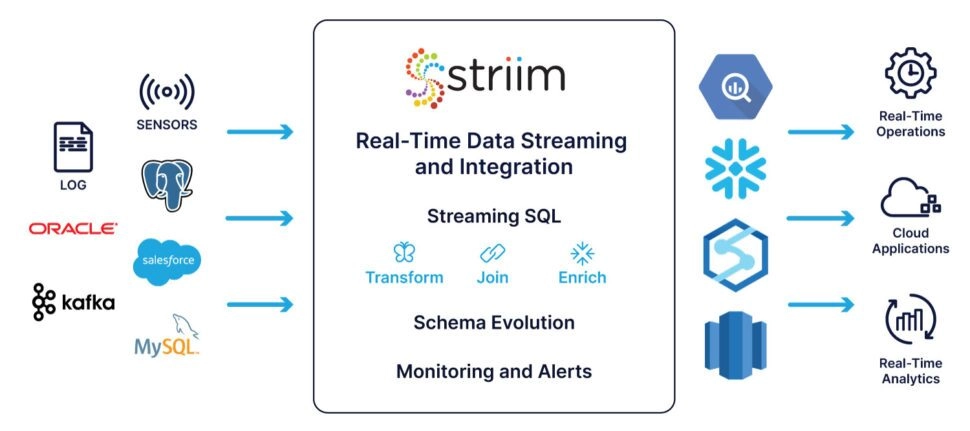
Striim is a complete, end-to-end, in-memory platform for collecting, filtering, transforming, enriching, aggregating, analyzing, and delivering data in real time. Built-in adapters collect data from and deliver data to SQL and no-SQL databases, data warehouses, applications, files, messaging systems, sensors, and more (see Sources and Targets for a complete list), on your premises or in the cloud. Integrated tools let you visualize live data in dashboards, explore it with SQL-like queries, and trigger alerts of anomalous conditions or security violations.
Collecting data

Striim ingests real-time streaming data from a variety of sources including databases, logs, other files, message queues, and devices. Sources are defined and configured using our TQL scripting language or the web UI via a simple set of properties. We also provide wizards to simplify creating data flows from common sources to popular targets.
Striim does not wait for files to be completely written before processing them in a batch-oriented fashion. Instead, the reader waits at the end of the file and streams out new data as it is written to the file. As such, it can turn any set of log files into a real-time streaming data source.
Similarly, Striim's database readers do not have to wait for a database to completely ingest, correlate, and index new data before reading it by querying tables. Instead, using a technology known as Change Data Capture (CDC), Striim non-intrusively captures changes to the transaction log of the database and ingests each insert, update, and delete as it happens.
A range of other sources are also available, including support for IoT and device data through TCP, UDP, HTTP, MQTT, and AMQP, network information through NetFlow and PCAP, and other message buses such as JMS, MQ Series, and Flume. (See Sources for a complete list.)
Data from all these sources can be delivered as is, or go through a series of transformations and enrichments to create exactly the data structure and content you need. Data can even be correlated and joined across sources.
Processing data
Typically, you will want to filter your source data to remove everything but that which matches certain criteria. You may need to transform the data through string manipulation or data conversion, or send only aggregates to prevent data overload. You may need to add additional context to the data. A lot of raw data may need to be joined with additional data to make it useful.
Striim simplifies these crucial data processing tasks—filtering, transformation, aggregation, and enrichment—by using in-memory continuous queries defined in TQL, a language with constructs familiar to anyone with experience using SQL. Filtering is just a WHERE clause. Transformations are simple and can utilize a wide selection of built-in functions, CASE statements, custom Java functions, and other mechanisms.
Aggregations utilize flexible windows that turn unbounded infinite data streams into continuously changing bounded sets of data. The queries can reference these windows and output data continuously as the windows change. This means a one-minute moving average is just an average function over a one-minute sliding window.
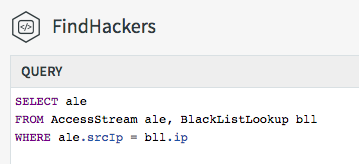
Enrichment uses external data introduced into Striim through the use of distributed caches (also known as data grids). Caches can be loaded with large amounts of reference data, which is stored in-memory across the cluster. Queries can reference caches in a FROM clause the same way as they reference streams or windows, so joining against a cache is simply a join in a TQL query.
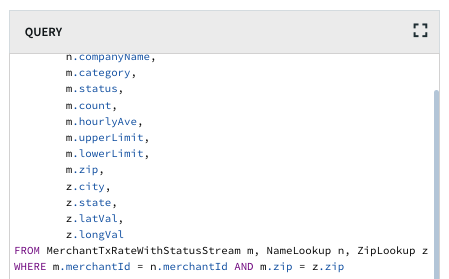
Multiple stream sources, windows, and caches can be used and combined together in a single query, and queries can be chained together in directed graphs, known as data flows. All of this can be built through the UI or our scripting language, and can be easily deployed and scaled across a Striim cluster, without having to write any additional code.
Analyzing data
Striim enables you to analyze data in memory, the same you process it—through SQL-like continuous queries. These queries can join data streams together to perform correlation, and look for patterns (or specific sequences of events over time) across one or more data streams utilizing an extensive pattern-matching syntax.
Continuous statistical functions and conditional logic enable anomaly detection, while built-in regression algorithms enable predictions into the future based on current events.
Analytics can also be rooted in understanding large datasets. Striim customers have integrated machine learning into data flows to perform real-time inference and scoring based on existing models. This utilizes Striim in two ways. First, Striim can prepare and deliver source data to targets in your desired format, enabling the real-time population of raw data used to generate machine learning models.
Then, once a model has been constructed and exported, you can easily call the model from our SQL, passing real-time data into it, to infer outcomes continuously. The end result is a model that can be frequently updated from current data, and a real-time data flow that matches new data to the model, spots anomalies or unusual behavior, and enables faster responses.
Visualizing data
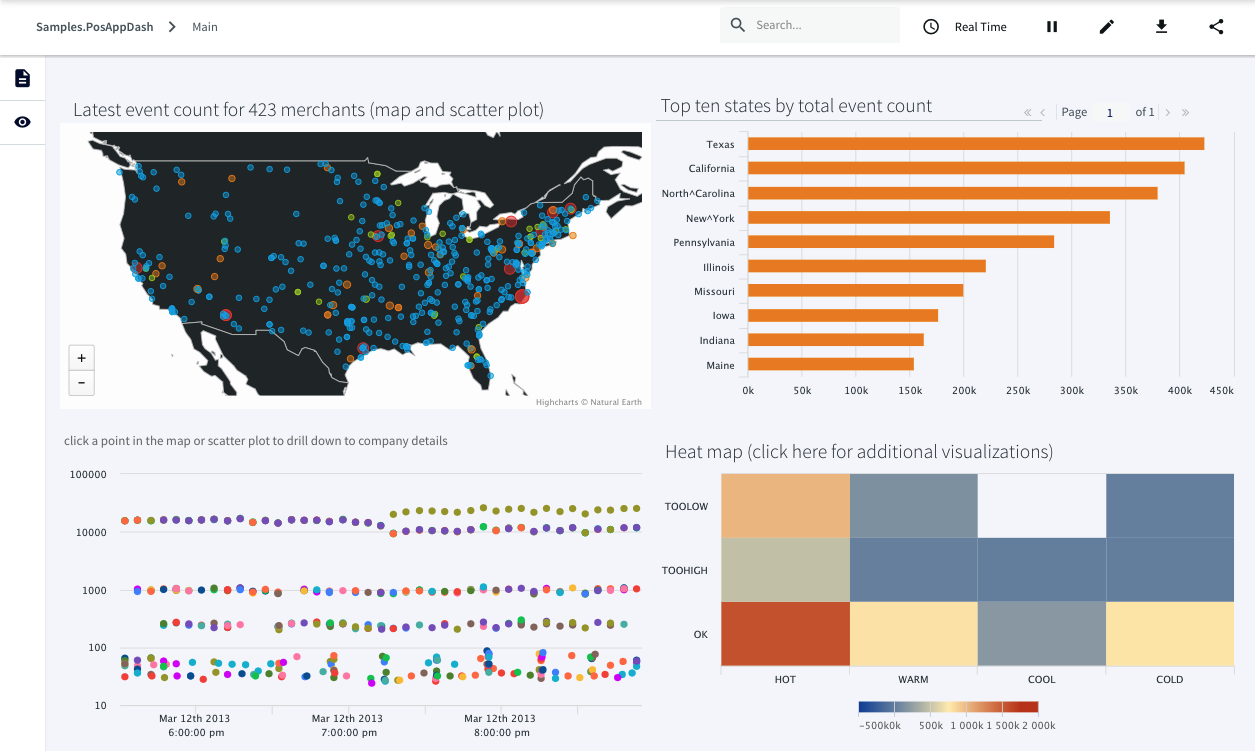
The final piece of analytics is visualizing and interacting with data. Striim includes a dashboard builder that lets you easily build custom, use-case-specific visualizations to highlight real-time data and the results of analytics. With a rich set of visualizations, and simple query-based integration with analytics results, dashboards can be configured to continually update and enable drill-down and in-page filtering.
Delivering data
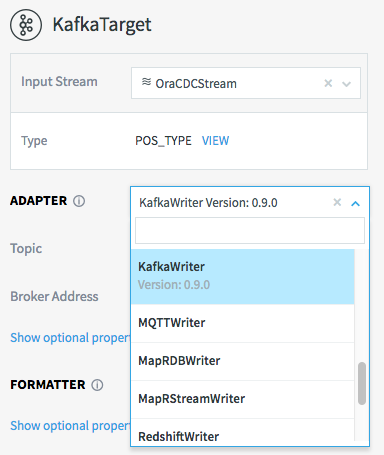
Striim can write continuously to a broad range of data targets, including databases, files, message queues, Hadoop environments, and cloud data stores such as Azure blob storage, Azure SQL DB, Amazon Redshift, and Google BigQuery (see Targets for a complete list). For targets that don't require a specific format, you may choose to format the output as Avro, delimited text, JSON, or XML. As with sources, targets are defined and configured using our TQL scripting language or the web UI via a simple set of properties, and wizards are provided for creating apps with many source-target combinations.
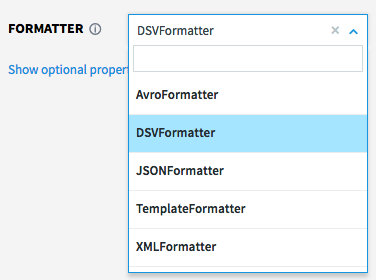
A single data flow can write to multiple targets at the same time in real time, with rules encoded as queries in between. For example, you can source data from Kafka and write some or all of it to Hadoop, Azure SQL DB, and your enterprise data warehouse simultaneously.
Putting it all together
Enabling all of these things in a single platform requires multiple major pieces of in-memory technology that have to be integrated seamlessly and tuned in order to be enterprise-grade. This means you have to consider the scalability, reliability, and security of the complete end-to-end architecture, not just a single piece.
Joining streaming data with data cached in an in-memory data grid, for example, requires careful architectural consideration to ensure all pieces run in the same memory space so joins can be performed without expensive and time-consuming remote calls. Continually processing and analyzing hundreds of thousands, or millions, of events per second across a cluster in a reliable fashion is not a simple task, and can take many years of development time.
Striim has been architected from the ground up to scale, and Striim clusters are inherently reliable with failover, recovery, and exactly-once processing guaranteed end to end, not just in one slice of the architecture.
Security is also treated holistically, with a single role-based security model protecting everything from individual data streams to complete end-user dashboards.
With Striim, you don't need to design and build a massive infrastructure, or hire an army of developers to craft your required processing and analytics. Striim enables data scientists, business analysts, and other IT and data professionals to get right to work without having to learn and code to APIs.
See our web site for additional information about what Striim is and what it can do for you: