Optimizing the performance of the Striim AI server
The performance settings described in this section apply only to Sentinel AI Agent nodes. These nodes use Striim AI for entity extraction and inference and support batch, parallel, and GPU-enabled execution modes.
To significantly boost the efficiency of data processing, Striim AI now uses batch processing and parallel execution instead of handling records individually. Records are grouped into batches and processed in parallel across a configurable pool of worker processes. This architecture, which includes both CPU and GPU utilization, has led to throughput improvements.
The following sections outline key performance tuning parameters that help optimize this architecture based on your hardware and accuracy needs.
Batch size and timeout
Striim AI now sends batches of records to the AI engine rather than individual records. The batch size (batchSize) and the maximum wait time before flushing a batch (batchTimeout) are both configurable parameters. This change improves throughput by allowing the system to process many records simultaneously.
Striim AI Basic: Recommended batch size is num_cpu_cores * 256, assuming sufficient RAM is available.
Striim AI Advanced: A fixed batch size of 128 works best across most environments.
Default configuration: Striim ships with a batch size of 128 and batch timeout of 5 seconds, providing good performance for most users.
The optimum batch size can vary depending on the size of the records being processed. The recommended values above are based on records approximately 175KB to 250KB in size. You can adjust these parameters to balance latency and throughput in your environment.
Striim AI modes: Basic vs Advanced
To optimize performance, the Striim AI server processes records in batches and leverages parallel processing. This architecture significantly increases throughput and scalability.
However, the choice between Basic and Advanced modes impacts both performance and accuracy:
Basic mode: CPU-only, about 10x faster than advanced mode, but with lower accuracy, particularly for fields like NAME and ADDRESS.
Advanced mode: Uses GPU and provides higher accuracy, especially for complex entity types.
Max workers (process pool size)
To process records in parallel, the Striim AI server uses a configurable process pool. This enables high concurrency by distributing record-level workloads across multiple CPU processes.
Recommended setting: (num_cores - 2) for systems with more than 2 cores, and 1 otherwise.
If you configure a higher value, Striim automatically caps the pool size and issues a warning to maintain optimal performance.
This setting directly affects throughput and should be tuned based on available CPU cores.
Configuration: The max worker process count is controlled on the Striim AI server side. Set the MAX_WORKERS environment variable in the shell or Docker environment before starting the Striim AI server:
Bash/Zsh: export MAX_WORKERS=8 csh/tcsh: setenv MAX_WORKERS 8
OpenAI and VertexAI performance tuning
Previously, LLMs like OpenAI and VertexAI were called synchronously for each record, leading to latency bottlenecks. Striim AI now uses parallel threads and async calls to LLMs, achieving up to 30x throughput gains with 16 threads.
Default threads: Set to 16, which is the optimal number for most current workloads.
Configurable Threads: This parameter can be adjusted, though increases beyond 16 haven’t yielded performance improvements yet.
Note
Cost implications: While more threads allow faster processing, total token usage does not increase. However, LLM providers impose rate limits (RPM and TPM) based on the customer’s subscription tier. Users requiring faster data processing may need to upgrade their plan to increase these limits.
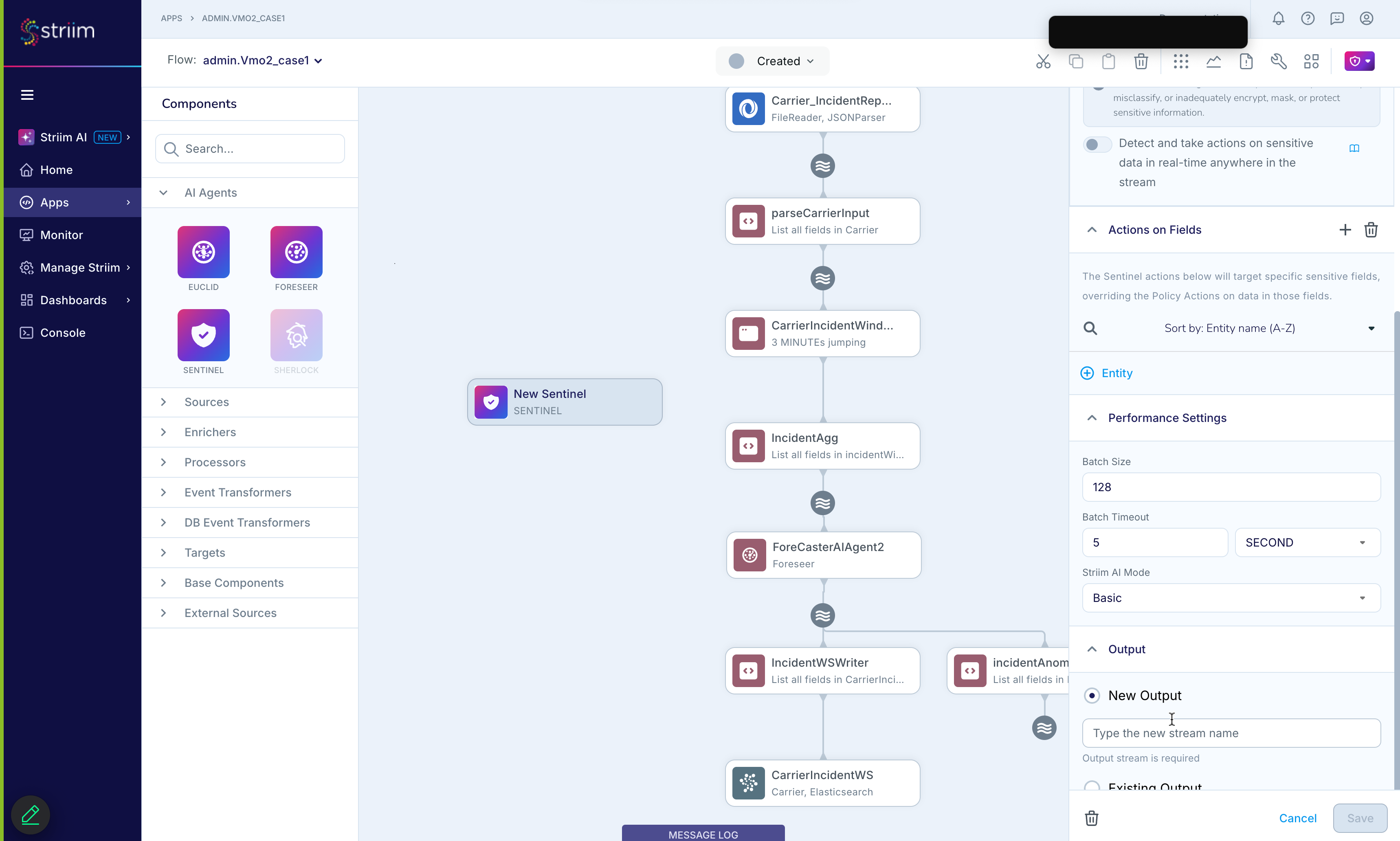
Configuring performance settings in Flow Designer
To apply these performance optimizations from the Flow Designer, open the configuration panel for a Sentinel AI Agent node and expand the Performance section.
From here, you can set:
Batch size: Controls how many records are grouped for each AI inference request.
Batch timeout: Sets the max wait time before sending a smaller-than-full batch.
Max workers: Limits the number of concurrent worker processes.
Striim AI mode: Specifies the processing mode used by the AI engine.
Basic: Optimized for speed using CPU-only execution. Provides lower latency but may reduce accuracy for certain entity types like locations or addresses.
Advanced: Uses GPU acceleration to improve prediction accuracy, especially for more complex fields. Suitable for production-quality results.
Recommended: Use Basic for development or low-latency needs; Advanced for higher accuracy in production workloads.
Note
Once you select OpenAI as your model provider, an additional performance option becomes available: the number of threads used for asynchronous inference. This controls how many parallel requests are sent to the LLM and can significantly affect throughput.
These settings allow you to tailor performance for your specific throughput, cost, and accuracy tradeoffs—without writing code or editing configuration files.