CREATE EXTERNAL SOURCE
Striim Connect enables integration of external data sources with the Striim platform through persisted streams backed by Kafka. External sources may include:
Kafka Connect source connectors (such as Debezium).
External readers such as Striim Agent for Db2 for z/OS or custom connectors that write directly to Kafka topics.
Kafka Connect is a component of Apache Kafka that provides a framework for building source and sink connectors. It is one common way to integrate external databases, key-value stores, and file systems with Kafka topics. Striim Connect can consume data written by Kafka Connect connectors, as well as data written by other external systems.
CREATE EXTERNAL SOURCE defines a metadata container in Striim that describes the external system, its data format, and associated schema registry. The External Source is not deployed as part of a Striim application. The actual data flow is managed through a persisted stream of type Global.WAEvent.
Features of Striim Connect
Striim Connect enables external systems to integrate with Striim's pipeline by reading from Kafka topics. Key features:
Infer Striim types from Debezium SourceRecords or Avro schemas.
Support initial snapshot loads and CDC events.
Publish monitoring metrics in Striim–compatible format.
Note
Striim Connect is not a source adapter—it integrates external Kafka source connectors to Striim via persisted streams.
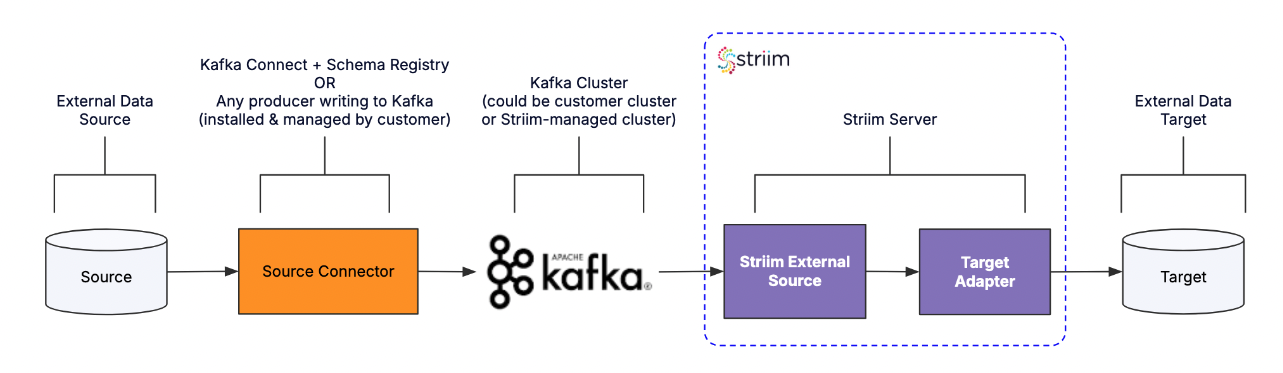
Support for reading from Debezium, Db2, and other sources
Striim Connect supports ingestion from:
Change events in
AvroDebeziumformat from Debezium connectors.External source data in
AvroExternalDb2zOSformat for Striim Agent for Db2 for z/OS pipelines.Other supported formats from Kafka source connectors.
Requirements for Debezium-based pipelines:
Messages must be Avro-encoded via Confluent Schema Registry.
Schemas must follow Debezium's
Envelopestandard structure.Kafka connector must reroute source tables into the persisted stream topic via regex transformation.
Configuring the Kafka source connector
Kafka source connectors must be configured to use:
AvroConverter with Schema Registry using
TopicRecordNameStrategy.Initial snapshot configuration (
snapshot.mode: initial).RegexRouter transformation to send data to the persisted stream topic.
E1P configuration (
exactly.once.source.support). Optional, if supported by connector.Recommended connector configs remain as outlined in this document.
Configuring Striim
Changes to stream configuration model
In earlier versions, dataformat and schemaregistry were defined in the persisted stream's PropertySet.
In current versions of Striim Connect, these properties are now defined on the CREATE EXTERNAL SOURCE entity.
This applies to:
AvroDebezium pipelines
AvroExternalDb2zOS (Striim Agent for Db2 for z/OS) pipelines
Future Kafka connector formats
The persisted stream itself is defined as a standard persisted stream and no longer requires dataformat or schemaregistry in its PropertySet.
External source properties
The following properties are used when creating an external source.
Property | Required? | Description |
|---|---|---|
SchemaRegistry | Yes | URL for the Schema Registry used by the Avro data publisher. |
SchemaRegistryconfig | No | Security properties for the Schema Registry. Supported authentication mechanisms are username/password based basic auth and TLS. |
Securing Schema Registry connections
To connect to a secure Schema Registry, define security properties under the SchemaRegistryconfig property. Supported authentication mechanisms are username/password based basic auth and TLS.
TLS
Transport Layer Security (TLS) provides privacy and authentication. With mTLS (Mutual Transport Layer Security), both the clients and the server authenticate each other.
Example: mTLS
SchemaRegistryConfig: '
ssl.keystore.location: <path_to_jks_keystore_file>,
ssl.keystore.password: <keystore_password>,
ssl.key.password: <private_key_password>,
ssl.truststore.location: <path_to_jks_truststore_file>,
ssl.truststore.password: <truststore_password> 'Example: TLS (one-way)
SchemaRegistryConfig: '
ssl.truststore.location: <path_to_jks_truststore_file>,
ssl.truststore.password: <truststore_password> 'Note
The default truststore and keystore type is JKS. A PKCS12 or PEM store can also be used with the additional properties ssl.truststore.type and ssl.keystore.type.
Basic authentication
Basic authentication uses username and password credentials to authenticate to the Schema Registry.
Example: Basic Auth
schemaregistryconfig: '
basic.auth.credentials.source=USER_INFO,
basic.auth.user.info=<username>:<password> 'Using Confluent Cloud
Confluent Cloud provides fully managed Kafka and Schema Registry services. This section describes how to configure Striim Connect to read from Confluent Cloud.
Confluent Cloud Schema Registry
Confluent Cloud Schema Registry uses username/password based authentication.
Example: External Source using Confluent Cloud Kafka and Schema Registry
create stream connect_data of Global.WAEvent
persist using Confluent_Kafka_PropSet;
create external source connect_source (
dataformat: 'AvroDebezium',
schemaregistry: '<confluent_cloud_schema_registry_url>',
schemaregistryconfig: '
basic.auth.credentials.source=USER_INFO,
basic.auth.user.info=<sr_api_key>:<sr_api_secret> '
) output to connect_data;Note
For the persisted stream configuration with Confluent Cloud Kafka, see Persisting a stream to Kafka.
Creating an External source using TQL
Example 1 — AvroDebezium:
CREATE STREAM example_data OF Global.WAEvent PERSIST;
CREATE EXTERNAL SOURCE example_source (
connector: 'exampleDB',
dataFormat: 'AvroDebezium',
schemaRegistry: 'http://10.0.0.92:8085'
)
OUTPUT TO example_data;
Example 2 — Striim Agent for Db2 for z/OS:
CREATE STREAM Db2zOSStream OF Global.WAEvent PERSIST;
CREATE EXTERNAL SOURCE Db2zOSReader (
connector: 'db2',
dataFormat: 'AvroExternalDb2zOS',
schemaRegistry: 'http://10.0.0.92:8085'
)
OUTPUT TO Db2zOSStream;
Optionally, you may create the persisted stream as part of CREATE EXTERNAL SOURCE:
CREATE EXTERNAL SOURCE <external source name> ( ... ) OUTPUT TO <stream name> PERSIST [USING <property set>];
If you do not specify a property set, the stream will be persisted using Striim's default Kafka property set. See Persisting a stream to Kafka for more information.
To list, describe, or remove:
LIST EXTERNAL SOURCES; DESCRIBE EXTERNAL SOURCE example_source; DROP EXTERNAL SOURCE example_source;
Configuring the persisted stream
The persisted streams that will receive data from Kafka source connectors must be created before starting the connectors. You must provide the name of the Kafka topic created by the persisted stream in the corresponding source connector configuration as its target.
The type of such persisted streams must be
Global.WAEvent. They cannot be of any other event type or user-defined type.No Striim component can write to persisted streams with
AvroDebeziumorAvroExternalDb2zOSdata formats. Striim components can only read from them. Kafka source connectors write to these topics.Important: For Striim Connect pipelines,
dataFormatandschemaRegistrymust now be specified in theCREATE EXTERNAL SOURCEdefinition, not in the PropertySet of the persisted stream.
Kafka topic lifecycle
Kafka topics are created by the persisted stream when it is created.
When the persisted stream is dropped, the associated Kafka topic is also dropped.
Use caution when deleting persisted streams used by external systems (such as Striim Agent for Db2 for z/OS), as other systems may rely on these topics.
TQL import/export limitations
CREATE EXTERNAL SOURCEstatements can be exported and imported between environments.DB2 CDC setup scripts (such as
setupDB2zOS) and related configuration files are not included in TQL exports or imports. These must be manually configured per environment.
Configuring target mapping in the Striim app
For the source database, the ordering of columns in the WAEvents coming out of the persisted stream will only match the ordering of columns in the source table if the primary key columns are defined in the table in order at the beginning of the column list. Otherwise, in the WAEvents, the primary key will appear first if it is a single key. If it is a composite key, there is no guarantee on the ordering of those columns. Also, there is no guarantee on ordering of the remaining non-primary-key columns.
For this reason, rather than assuming the source table column ordering, you should use explicit column mapping by name in the target mappings.
Database mapping
Any source database data will be written to the Kafka topic as one the Avro datatypes. This may cause loss of type information as Avro types are limited compared to the source databases. To mitigate this issue, Debezium provides an optional Semantic Type with every Literal Type (Avro schema type) definition with the data records. The source connectors must provide the semantic types for data when required for correct datatype handling by Striim Connect.
If a semantic type is present, the following is the datatype mapping from Avro data to Striim events:
Semantic type | Description | Literal type | Java type |
|---|---|---|---|
io.debezium.time.Date | # of days since the epoch | int | java.time.LocalDate |
io.debezium.time.Time | # of milliseconds past midnight | int | java.time.LocalTime |
io.debezium.time.MicroTime | # of microseconds past midnight | long | java.time.LocalTime |
io.debezium.time.NanoTime | # of nanoseconds past midnight | long | java.time.LocalTime |
io.debezium.time.Timestamp | # of milliseconds past the epoch | long | java.time.LocalDateTime |
io.debezium.time.MicroTimestamp | # of microseconds past the epoch | long | java.time.LocalDateTime |
io.debezium.time.NanoTimestamp | # of nanoseconds past the epoch | long | java.time.LocalDateTime |
io.debezium.time.ZonedTimestamp | timestamp in ISO 8601 format | String | java.time.LocalDateTime |
org.apache.kafka.connect.data.Date | # of days since the epoch | int | java.time.LocalDate |
org.apache.kafka.connect.data.Time | # of microseconds past midnight | long | java.time.LocalTime |
org.apache.kafka.connect.data.Timestamp | # of milliseconds since epoch | long | java.time.LocalDateTime |
If there is no semantic type, the following is the datatype mapping from Avro data to Striim events:
Literal type | Java type | Notes |
|---|---|---|
boolean | java.lang.Boolean | |
int | java.lang.Integer | |
long | java.lang.Long | |
float | java.lang.Float | |
double | java.lang.Double | |
string | java.lang.String | |
enum | java.lang.String | |
fixed | java.lang.String | |
bytes | java.lang.String | Hex encoded. |
array | java.lang.String | Comma separated, curly bracket enclosed. |
Setting up the environment for Striim Connect
The following steps show an example of setting up the environment for Striim Connect. These steps may vary depending on your source and target.
Setup Kafka Broker. Download Kafka 3.3.2 (or above). Start Zookeeper and a Kafka broker.
Setup Confluent Schema Registry. For example:
docker run -it --rm --name csr -p 8085:8085 -e SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS=<kafka_broker_ip>:9092 -e SCHEMA_REGISTRY_HOST_NAME=localhost -e SCHEMA_REGISTRY_LISTENERS=http://0.0.0.0:8085 -e SCHEMA_REGISTRY_KAFKASTORE_TIMEOUT_MS=5000 confluentinc/cp-schema-registry:latest
Setup Kafka Connect service with the connector plugin. For example:
docker run -it --rm --name connect -p 8083:8083 -e BOOTSTRAP_SERVERS=<kafka_broker_ip>:9092 -e GROUP_ID=connect_cluster -e CONFIG_STORAGE_TOPIC=connect_configs -e OFFSET_STORAGE_TOPIC=connect_offsets -e STATUS_STORAGE_TOPIC=connect_status quay.io/yugabyte/debezium-connector:latest
Set up the database instance. For example:
docker run -d -p 7000:7000 -p 7100:7100 -p 9000:9000 -p 9100:9100 -p 15433:15433 -p 5433:5433 -p 9042:9042 --name yugabyte yugabytedb/yugabyte:latest bin/yugabyted start --daemon=false
In docker perform the following steps:
Check the host and port of the instance.
Connect to Yugabyte SQL (YSQL), create a few tables as the data sources, and insert data in the tables.
Create a change data stream.
docker exec -it yugabyte /bin/bash (a) yugabyted status (b) bin/ysqlsh -h <docker_host_ip> -U yugabyte -d yugabyte (c) bin/yb-admin --master_addresses <docker_host_ip>:7100 create_change_data_stream ysql.yugabyte IMPLICIT ALL
Note the CDC Stream ID, it will be required in the connector configuration.
Setup PostgreSQL as the target database. Create the target tables in the database.
docker run -d -p 5432:5432 --name postgres12 123456789012.dkr.ecr.us-west-1.amazonaws.com/postgres-12.2:latest
Start the Striim server. The following sample TQL creates an external stream and write to the PostgreSQL target:
create application demo recovery 30 second interval; create PropertySet KConnPropSet ( zk.address: '<ip-address>:<port>', bootstrap.brokers: '<ip-address>:<port>', kafkaversion: '2.1', partitions: '1', replication.factor: '1', dataformat: 'avro-debezium', schemaregistry: 'http://<ip-address>:<port>' ); create stream yb_data of Global.WAEvent persist using KConnPropSet; create external source yb_source ( connector: 'yugabyteDB' ) output to yb_data; create target pg_replica using Global.DatabaseWriter ( ConnectionURL:'jdbc:postgresql://<postgresql_ip>:<port/example>', ConnectionRetryPolicy: 'retryInterval=5, maxRetries=3', CDDLAction: 'Process', Username:'<example>', Password:'<example>', BatchPolicy:'Eventcount:10,Interval:10', CommitPolicy:'Interval:10,Eventcount:10', Tables: '<list_of_table_mappings>' ) input from yb_data; create target con_disp using SysOut(name:Disp) input from yb_data; end application demo; deploy application demo; start demo;Start the source connector.
curl -H "Content-Type: application/json" -X POST http://<kafka_connect_ip>:8083/connectors -d @"debezium-yugabyte-source-connector.json"
Configure the source connector as follows:
{ "name" : "debezium-yugabyte-source-connector", "config": { "connector.class" : "io.debezium.connector.yugabytedb.YugabyteDBConnector", "tasks.max" : 1, "snapshot.mode" : "initial", "exactly.once.support" : "requested", "database.hostname" : "<yugabytedb_ip>", "database.port" : 5433, "database.master.addresses" : "<yugabytedb_ip>:7100", "database.user" : "yugabyte", "database.password" : "yugabyte", "database.dbname" : "yugabyte", "database.server.name" : "dbserver1", "database.streamid" : "<cdc_stream_id>", "table.include.list" : "<list_of_tables>", "tombstones.on.delete" : false, "topic.creation.enable" : true, "topic.prefix" : "debezium", "topic.creation.default.partitions" : 1, "topic.creation.default.replication.factor" : 1, "include.schema.changes" : true, "schema.history.internal.kafka.bootstrap.servers" : "<kafka_broker_ip>:9092", "schema.history.internal.kafka.topic" : "debezium_schemahistory", "key.converter" : "io.confluent.connect.avro.AvroConverter", "value.converter" : "io.confluent.connect.avro.AvroConverter", "key.converter.schema.registry.url" : "http://<schema_registry_ip>:8085", "value.converter.schema.registry.url" : "http://<schema_registry_ip>:8085", "key.converter.key.subject.name.strategy" : "io.confluent.kafka.serializers.subject.TopicRecordNameStrategy", "value.converter.value.subject.name.strategy": "io.confluent.kafka.serializers.subject.TopicRecordNameStrategy", "transforms" : "Reroute", "transforms.Reroute.type" : "org.apache.kafka.connect.transforms.RegexRouter", "transforms.Reroute.regex" : ".*", "transforms.Reroute.replacement" : "admin_yb_data" } }The existing records from the source database tables will appear in the PostgreSQL tables. Do some DMLs in the source database tables, and verify that they appear in the PostgreSQL tables.
Note
Another option for testing Striim Connect is to configure and test the Kafka Connect components separately from the Striim components before combining them together. First set up the infrastructure and test data flow from the source database to the Kafka topic. Then test the actual Striim Connect functionality and verify that Striim is able to read from the Kafka topic and deliver to the targets.