Select schemas and tables to sync
Select schemas
Select the source schemas containing the tables you want Striim to sync to Databricks, then click Next.
The first time you run the pipeline, Striim will create target databases in Databricks with the same names as the selected schemas automatically.
Note
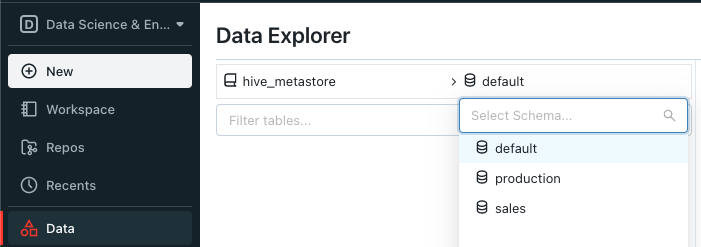
In Databricks, you will find the schemas created by Striim in the Data section of the Data Science & Engineering persona, not the SQL persona. See Learn / Navigate the workspace / Use the sidebar for more information. If you did not specify a catalog name in the Databricks connection properties, the schemas will be in the default hive_metastore.
Select tables
Select the source tables you want Striim to sync to Databricks, then click Next.
The first time you run the pipeline, Striim will create tables with the same names, columns, and data types in the target datasets.
For information on supported datatypes and how they are mapped between your source and Databricks, see Data type support & mapping for schema conversion & evolution.